热度 1 |
对于很多人来说,python的中字符转码是一件很头疼的事情,本来期望结果输出的是中文,结果来一段像这样\xe4\xbd\xa0\xe5\xa5\xbd像是乱码的字符串。
由于学python没多久,昨天使用python的时候,就遇到这种问题,现在来深入研究下与之相关的encode()和decode()函数,和如何把如乱码般的字符串转成中文。
encode()和decode()都是字符串的函数,可直接查看关于python字符串章节的官方文档:
https://docs.python.org/3/library/stdtypes.html?highlight=encode#string-methods
从英文意思上看,encode和decode分别指编码和解码。在python中,Unicode类型是作为编码的基础类型,即:

简要说下一般有哪些编码格式。
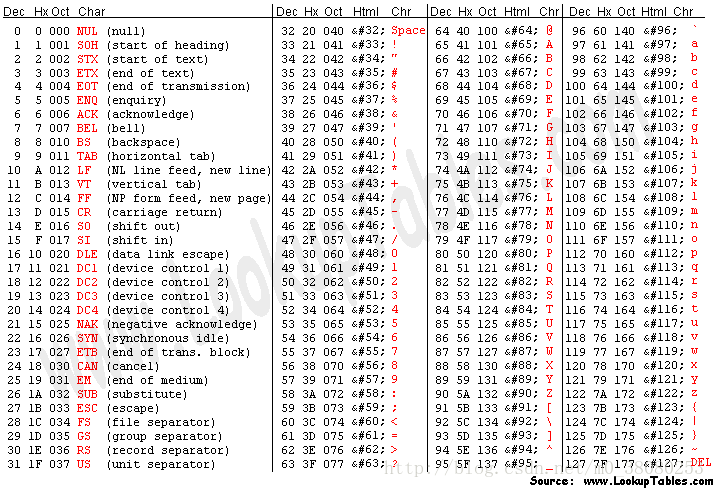
ASCII码ASCII码是美国早期制定的编码规范,只能表示128个字符,包括英文字符、阿拉伯数字、西文字符以及32个控制字符。简单来说,就是下面这个表:
简单而言,扩展ASCII码的出现是因为ASCII不够用,所以向ASCII表继续扩充到256个符号。
但是因为对于扩展ASCII,不同的国家有不同的标准,于是促使了Unicode编码的诞生。
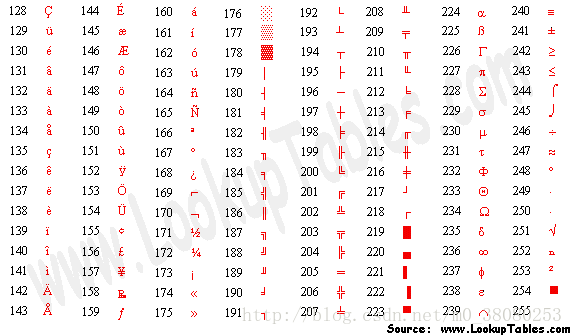
扩展ASCII码表如下:
准确来说,Unicode不是编码格式,而是字符集。这个字符集包含了世界上目前所有的符号。
另外,在原来有些字符可以用一个字节即8位来表示的,在Unicode将所有字符的长度全部统一为16位,因此字符是定长的。
Unicode是长这样的:
上面这段Unicode的意思是“你好中国!hello,123”。
小黑屋|手机版|Archiver|鱼C工作室
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
GMT+8, 2024-4-19 08:20
Powered by Discuz! X3.4
© 2001-2023 Discuz! Team.