测试题:
0. 请问 URL 是“统一资源标识符”还是“统一资源定位符”?
答:Uniform Resource Locator,统一资源定位符
1. 什么是爬虫?
答:互联网就是一张网,爬虫就是一个爬取这张网上的数据的程序。
2. 设想一下,如果你是负责开发百度蜘蛛的攻城狮,你在设计爬虫时应该特别注意什么问题?
答:关键字的设定和排序。
3. 设想一下,如果你是网站的开发者,你应该如何禁止百度爬虫访问你网站中的敏感内容?(课堂上没讲,可以自行百度答案)
答:
搜索引擎默认的遵守robots.txt协议,创建robots.txt文本文件放至网站根目录下,编辑代码如下:
User-agent: BaiduSpider
Disallow: /
4. urllib.request.urlopen() 返回的是什么类型的数据?
答:bytes类型,需要decode()解码转换为str类型
5. 如果访问的网址不存在,会产生哪类异常?(虽然课堂没讲过,但你可以动手试试)
答:
TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
urllib.error.URLError: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
答:utf-8
7. 为了解决 ASCII 编码的不足,什么编码应运而生?
答:Unicode,然后utf-8
答:
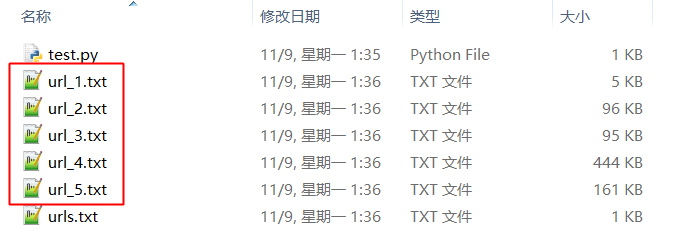
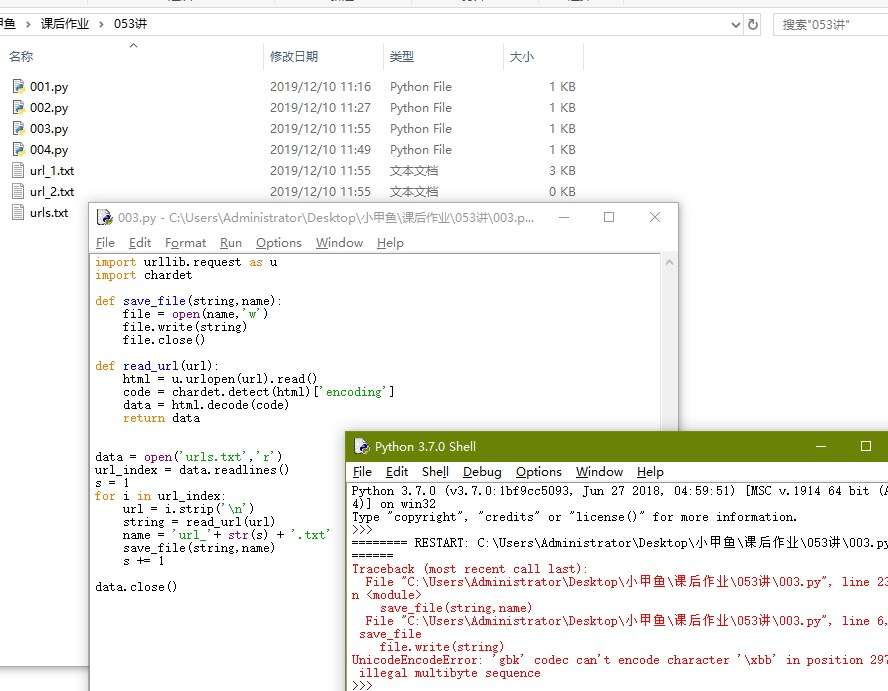
2. 写一个程序,依次访问文件中指定的站点,并将每个站点返回的内容依次存放到不同的文件中。
演示:
urls.txt 文件存放需要访问的 ULR:
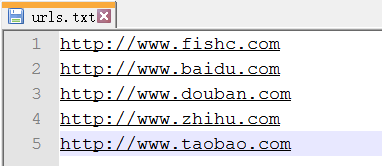
执行你写的程序(test.py),依次访问指定的 URL 并将其内容存放为一个新的文件




 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)





