|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
- #-*-coding:utf-8 -*-
- import requests
- from lxml import etree
- import time #这里导入时间模块,以免豆瓣封ip
- url ='https://movie.douban.com/subject/3231742/'
- data = requests.get(url).text
- s=etree.HTML(data)
- #给定并用requests.get()方法来获取页面的text,用etree.HTML()
- #来解析下载的页面数据“data”
- film_name = s.xpath('//*[@id="content"]/h1/span[1]/text()')
- print("电影名:",film_name)
运行的时候总是报这个问题:
Traceback (most recent call last):
File "E:\eclipse\Python1\python1\__init__.py", line 15, in <module>
film_name = html.xpath('//*[@id="content"]/h1/span[1]/text()')
AttributeError: 'NoneType' object has no attribute 'xpath'
请问应该怎么解决呢?
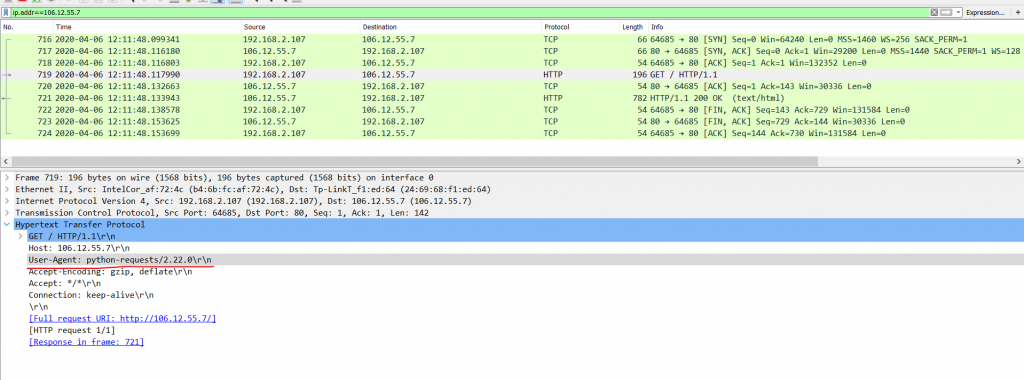
不加头拿不到数据
headers = {'user-agent':'firefox'}
data = requests.get(url, headers=headers).text
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-4-1 16:26:44
发表于 2020-4-1 16:26:44
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-4-1 16:42:55
发表于 2020-4-1 16:42:55

 楼主
楼主