|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
Python 中有五大标准数据类型,分别是 数字、字符串、列表、元组 和 字典。
- 列表中的元素可以是任意类型的,并且同一个列表中的元素类型也可以不统一,下面的列表在 Python 中都是正确的:
- list1 = [1, 2, 3] # 元素是数字
- list2 = ['a', 'b', 'c'] # 元素是字符串
- list3 = [(1, 2), (3, 4), (5, 6)] # 元素是元组
- list4 = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # 元素是列表
- list5 = ['a', 1, 'c'] # 元素是字符串和数字
列表中还有一个比较重要的知识点就是 索引 和 分片。它们都是列表的查找操作。索引查找的是单个元素,格式是 列表[索引],支持正向和反向索引;分片查找的是一个范围内的元素,格式是 列表[起始索引:结束索引],其中结束索引是选取范围的最后一个元素的索引值+1。
- list4 = [
- [1, 2, 3],
- [4, 5, 6],
- [7, 8, 9]
- ]
- # 找出 list4 中第二个元素
- print(list4[1])
- # 输出 [4, 5, 6]
- # 找出 list4 中,第二个元素的第三个元素
- print(list4[1][2])
- # 输出:6
- 这就相当于,我们通过两步索引,找出了这个表格中位于第 2 行第 3 列的元素。如果我们要取某行某列的元素,那通用格式就是 列表[行数-1][列数-1]。
计算排名记得+1+1+1!!!!
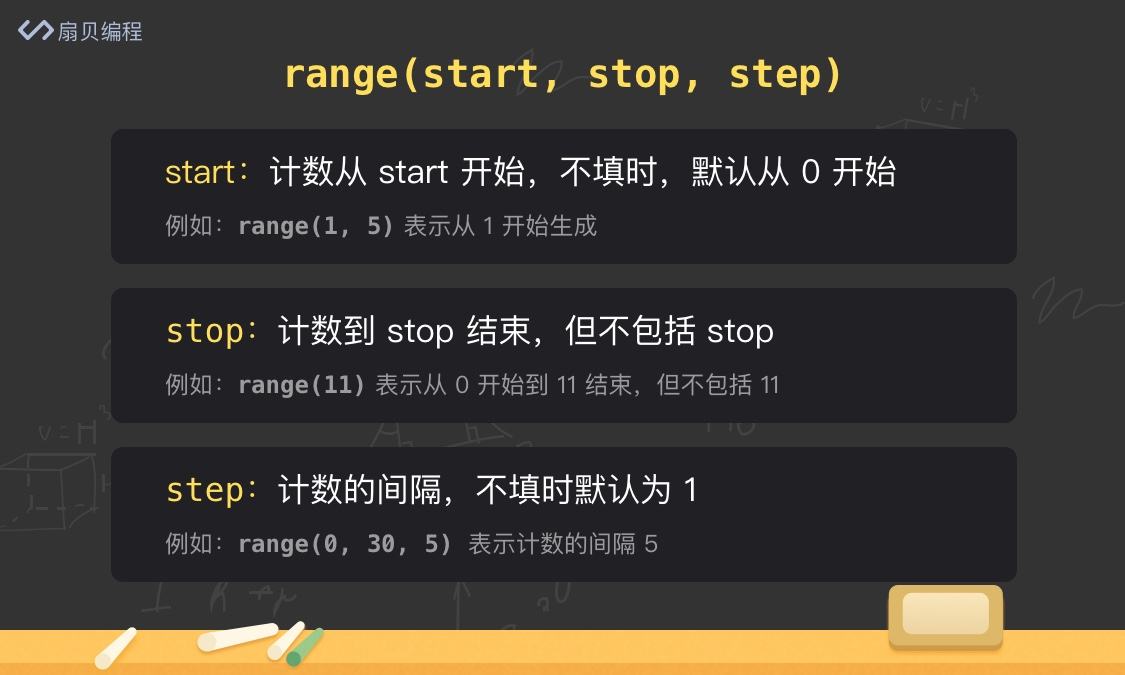
range() 函数最多支持 3 个参数,start 参数是起始元素,stop 参数是结束元素,step 是步长,也就是计数的间隔。其中 start 和 step 是可选的,分别默认为 0 和 1,比如 list(range(3)) 可以快速生成 [0, 1, 2] 列表。
聪明的你一定已经发现,range() 的取值逻辑,和列表的切片是一样的, 选取范围包括起始位置,却不包括结束位置。这也是和我们之前说的切片设计逻辑是一样的道理,方便我们快速看出范围的元素数目。
错误Q
0也可以被3整除...
- test_scores = [100, 97, 76, 84, 93, 98, 86, 92, 76, 88, 95, 90, 95, 93]
- new_scores = test_scores.sort()
- new_scores = new_scores.reverse()
- print(new_scores)
- # 报错:AttributeError: 'NoneType' object has no attribute 'reverse' in line 3.
- #(属性错误:第三行中,NoneType 对象没有 reverse 属性。)
这样写是不可以的,因为 sort() 和 reverse() 方法只是对原来的列表进行操作,不会生成新的列表,所以它们是没有返回值的,或者说,返回的是 None。因此,第二行中,new_scores 赋到的值是 None,再对 None 调用 reverse() 方法当然会出错。
- test_scores = [100, 97, 76, 84, 93, 98, 86, 92, 76, 88, 95, 90, 95, 93]
- # 直接操作原列表
- test_scores.sort()
- # 直接操作原列表
- test_scores.reverse()
- print(test_scores)
- # 输出:[100, 98, 97, 95, 95, 93, 93, 92, 90, 88, 86, 84, 76, 76]
直接对原表操作
拓展:在前面方法复习小节图片中列表方法中,除了 copy()、index()、count() 和 pop() 四个方法会返回对应的结果,其它的方法都是遵照“仅处理原列表,不返回新值”的规则。
索引是列表中元素的个数减 1(或者用反向索引,直接用 -1 即可),一定要谨记于心。
未完待续!
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-8-1 22:22:20
发表于 2020-8-1 22:22:20
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡