|
|

楼主 |
发表于 2020-8-8 19:59:01
|
显示全部楼层
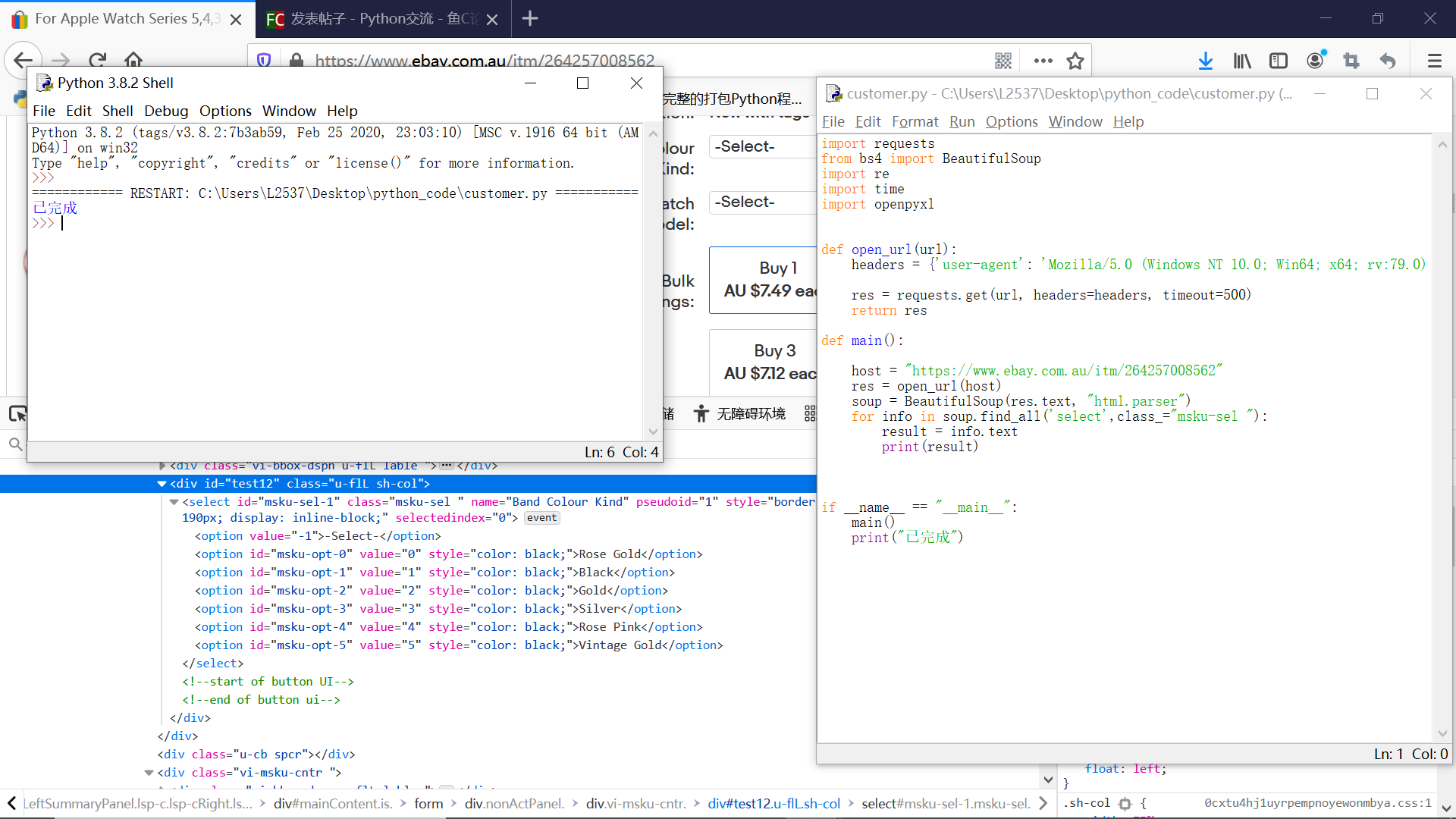
import requests
from bs4 import BeautifulSoup
import re
import time
import openpyxl
def open_url(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0'}
res = requests.get(url, headers=headers, timeout=500)
return res
def main():
host = "https://www.ebay.com.au/itm/264257008562"
res = open_url(host)
soup = BeautifulSoup(res.text, "html.parser")
for info in soup.find_all('select',class_="msku-sel "):
result = info.text
print(info["id"])
if __name__ == "__main__":
main()
print("已完成") |
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-8-8 19:53:43
发表于 2020-8-8 19:53:43

 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-8-8 19:56:21
发表于 2020-8-8 19:56:21
