|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
本帖最后由 极品召唤兽 于 2020-8-12 22:36 编辑
列表能进行一一对应 字典也可以做到
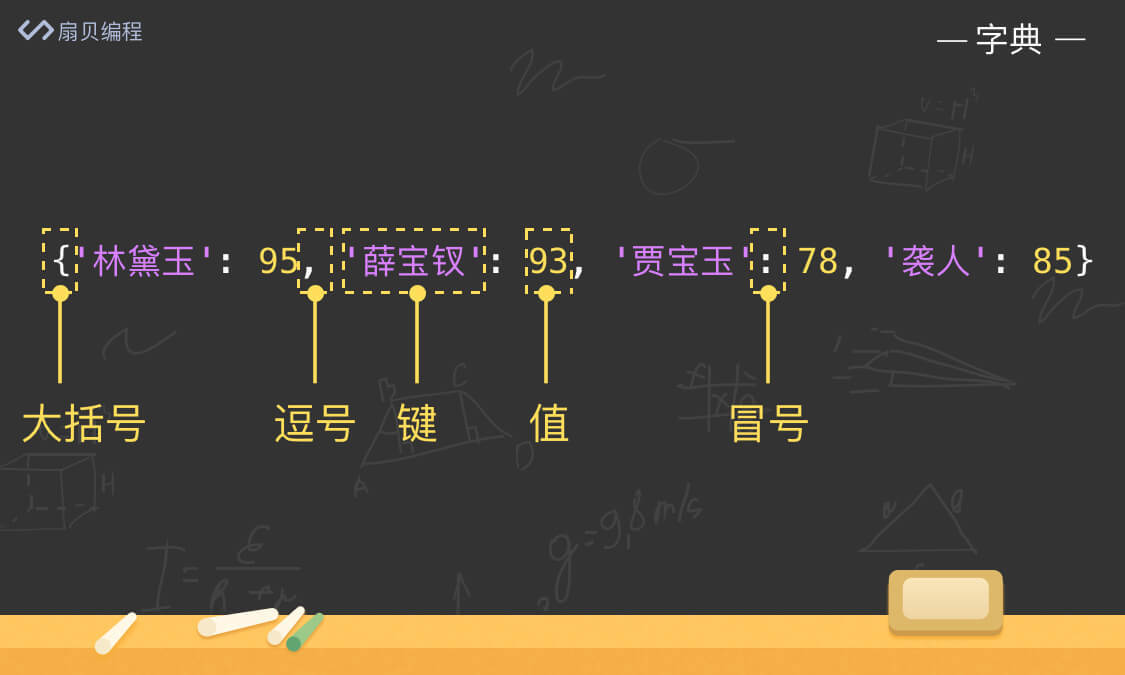
我们可以看到,字典 是由一对大括号({})包裹着的。和列表不同的是,字典的每个元素是 键值对,如 '林黛玉': 95,其中我们把 '林黛玉' 叫 键(key),95 叫 值(value),中间用冒号连接(:)。
需要注意的是,字典中的 键 需要是 唯一的,如果字典中有两个相同的 键,Python 只会保留后面那个。而 值 则没有限制,可以是任意类型的,也可以有相同的值。
- # 一行太长放不下的时候也可以换行
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78,
- '林黛玉': 78
- }
- print(scores)
- # 输出:{'林黛玉': 78, '薛宝钗': 93, '贾宝玉': 78}
拓展:字典在 Python 3.6 之前无序的,所以创建字典时的顺序不影响结果。
字典的取值
接下来我们来看一下如何进行字典的取值。和列表类似,访问字典中的元素也使用方括号([])。不同的是,列表中括号内的是 索引,字典中括号内的是 键。看个例子你就明白了:
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78
- }
- print(scores['林黛玉'])
- # 输出:95
字典元素的修改/添加/删除
字典元素的修改/添加/删除其实非常简单,我们来通过几个例子了解一下:
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78
- }
- # 修改
- scores['林黛玉'] = 90
- print(scores)
- # 输出:{'林黛玉': 90, '薛宝钗': 93, '贾宝玉': 78}
- # 添加
- scores['袭人'] = 85
- print(scores)
- # 输出:{'林黛玉': 90, '薛宝钗': 93, '贾宝玉': 78, '袭人': 85}
- # 删除
- del scores['林黛玉']
- print(scores)
- # 输出:{'薛宝钗': 93, '贾宝玉': 78, '袭人': 85}
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78,
- '袭人': 85
- }
- print(scores.keys())
- # 输出:dict_keys(['林黛玉', '薛宝钗', '贾宝玉', '袭人'])
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78,
- '袭人': 85
- }
- print(scores.values())
- # 输出:[95, 93, 78, 85]
items()
用于获取字典中所有的 键 + 值 元组。
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78,
- '袭人': 85
- }
- print(scores.items())
- # 输出:[('林黛玉', 95), ('薛宝钗', 93), ('贾宝玉', 78), ('袭人', 85)]
- # 使用循环遍历字典的键和值
- for name, score in scores.items():
- print('%s的分数是:%d' % (name, score))
- # 输出:
- # 林黛玉的分数是:95
- # 薛宝钗的分数是:93
- # 贾宝玉的分数是:78
- # 袭人的分数是:85
注意:keys()、values() 和 items() 方法在 Python3 中返回的是有序序列,必要时需要用 list() 函数转换成列表使用,如 list(scores.keys())。
get()
通过 键 获取字典对应的值,当 键 不存在于字典当中时不会报错,而是默认返回 None,也可以通过第二个参数设置不存在时的默认返回值。
- scores = {
- '林黛玉': 95,
- '薛宝钗': 93,
- '贾宝玉': 78,
- '袭人': 85
- }
- print(scores.get('林黛玉'))
- # 输出:95
- print(scores.get('小贝'))
- # 输出:None
- print(scores.get('小贝', '小贝没参加编程考试'))
- # 输出:小贝没参加编程考试
字典嵌套
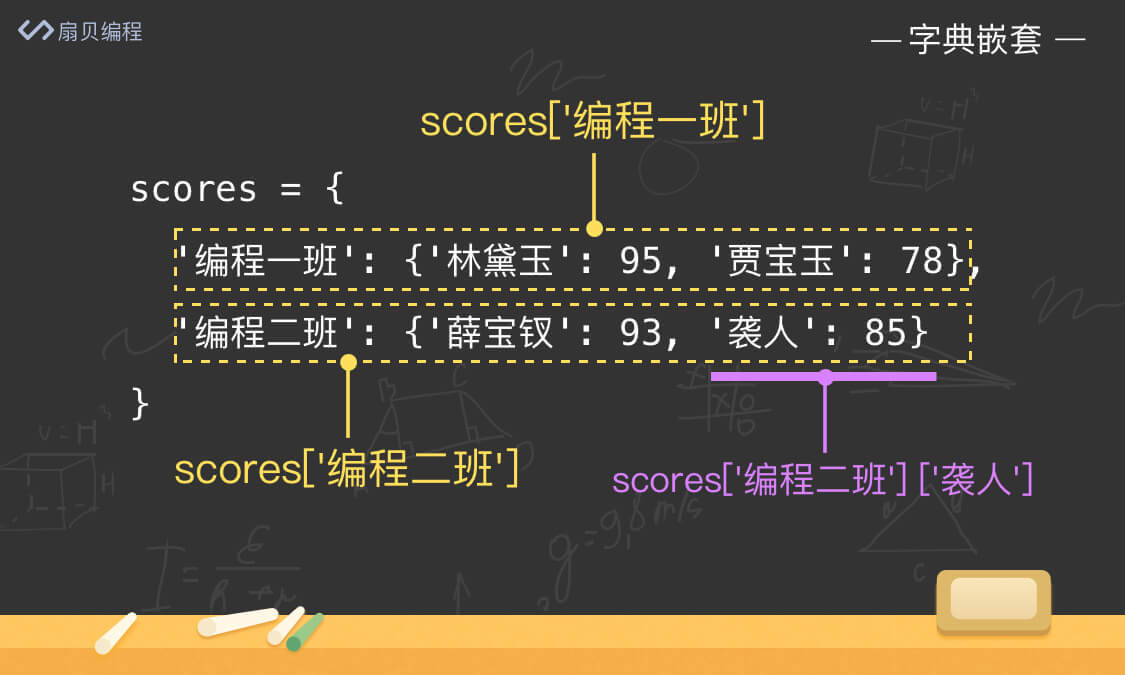
我们之前说过,字典的 键 是 唯一不可变的,而字典的 值 是没有限制的。所以,当字典的值为字典时,就形成了字典的嵌套。举个例子:
- scores = {
- '编程一班': {
- '林黛玉': 95,
- '贾宝玉': 78
- },
- '编程二班': {
- '薛宝钗': 93,
- '袭人': 85
- }
- }
- print(scores)
- # 输出:{'编程一班': {'林黛玉': 95, '贾宝玉': 78}, '编程二班': {'薛宝钗': 93, '袭人': 85}}
嵌套字典要怎么取值呢?其实很简单,比如我们要访问林黛玉的分数,首先访问第一层 编程一班,接着再访问里面的 林黛玉 即可。
- scores = {
- '编程一班': {
- '林黛玉': 95,
- '贾宝玉': 78
- },
- '编程二班': {
- '薛宝钗': 93,
- '袭人': 85
- }
- }
- print(scores['编程一班'])
- # 输出:{'林黛玉': 95, '贾宝玉': 78}
- print(scores['编程一班']['林黛玉'])
- # 输出:95
- temperatures = {'country': '中国', 'provinces': [
- {
- 'name': '江苏', 'cities': [
- {'name': '南京', 'temperature': '32度'},
- {'name': '苏州', 'temperature': '31度'}]
- },
- {
- 'name': '四川', 'cities': [
- {'name': '成都', 'temperature': '37度'},
- {'name': '绵阳', 'temperature': '34度'}]
- },
- {
- 'name': '广东', 'cities': [
- {'name': '深圳', 'temperature': '30度'},
- {'name': '广州', 'temperature': '33度'}]
- }
- ]}
- for province in temperatures['provinces']:
- for city in province['cities']:
- print('{}-{}的温度是{}'.format(province['name'], city['name'], city['temperature']))
死亡练习
大家肯定都摇过 🎲,我们知道一个骰子有六个面,分别对应 1-6 六个数字,这六个数字出现的概率是一样的,都是六分之一(0.166666...)。
接下来我们来用 Python 验证一下,我们摇 1000 次骰子并统计每个数字出现的次数,然后将每个数字出现的次数除以总次数得出每个数字出现的概率。
Tips:使用 random.choice() 来模拟摇骰子。
- import random
- b = {"1": 0, "2": 0, "3": 0, "4": 0, "5": 0, "6": 0}
- t = 2000
- for i in range(t):
- a = random.choice(('1','2','3','4','5','6'))
- b[a] +=1
-
- for a,b in b.items():
- print('数字{}的概率是{}'.format(a,b/t))
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-8-12 22:36:20
发表于 2020-8-12 22:36:20


 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡