|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
- def file_reaplace(file_name,rep_word,new_word):
- f_read = open(file_name,encoding='UTF-8')
- content = []
- count = 0
- for eachline in f_read:
- if rep_word in eachline:
- count = eachline.count(rep_word)
- eachline = eachline.replace(rep_word,new_word)
- content.append(eachline)
- decide = input('文件 %s 中共有 %s 个【 %s 】\n您确定要把所有的【 %s 】替换为【 %s 】吗?\n【Yes/No】:'% (f_read,count,rep_word,rep_word,new_word))
- if decide in 'YesyesYES':
- f_write = open(file_name,'w')
- f_write.writelines(content)
- f_write.close()
- f_read.close()
- file_name = input('请输入文件名:')
- rep_word = input ('请输入需要替换的单词或字符:')
- new_word = input('请输入新的单词或字符:')
- file_reaplace(file_name,rep_word,new_word)
各位大佬好,我按小甲鱼的程序写的,为什么还会报错?
Traceback (most recent call last):
File "D:/pycharm/main.py", line 25, in <module>
file_reaplace(file_name,rep_word,new_word)
File "D:/pycharm/main.py", line 7, in file_reaplace
for eachline in f_read:
File "D:\python37\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbf in position 2: invalid start byte
这是编码错误,是 open 函数打开文件时候解码和你 txt 文件编码不一致导致的
把你 open 参数那的 encoding = 'UTF-8' 去掉试试看,应该就可以正常运行了
如果还是不能正常运行,说明你文件夹中有两种编码不同 txt 的文件,但是 open 只设置了其中一种,导致另一种读取汉字字节不同而报错
建议这个时候重新创个文件夹,以及重新新建 txt 文件在文件夹中,用代码查找这个文件夹里面的 txt ,应该就能成功运行
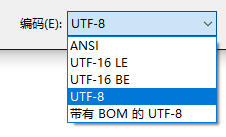
想更改 txt 文本的编码可以在保存时候进行设置:
若选择 UTF-8 那么 open 参数中需要带上 encoding = 'utf-8' ,如果懒得加这个参数,你选择 ANSI 即可
国内大部分电脑的 ANSI 都是默认 GBK 编码 ,而 open 也是默认 gbk 读取的,所以可以直接进行解码
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-11-8 21:35:06
发表于 2020-11-8 21:35:06
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-11-8 21:42:16
发表于 2020-11-8 21:42:16

 发表于 2020-11-8 21:44:12
发表于 2020-11-8 21:44:12