|
|
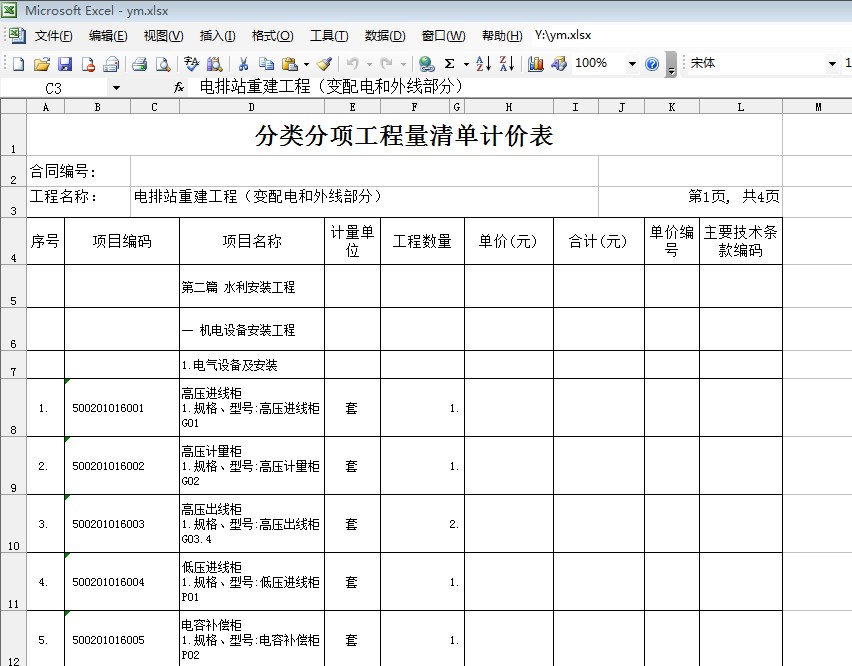
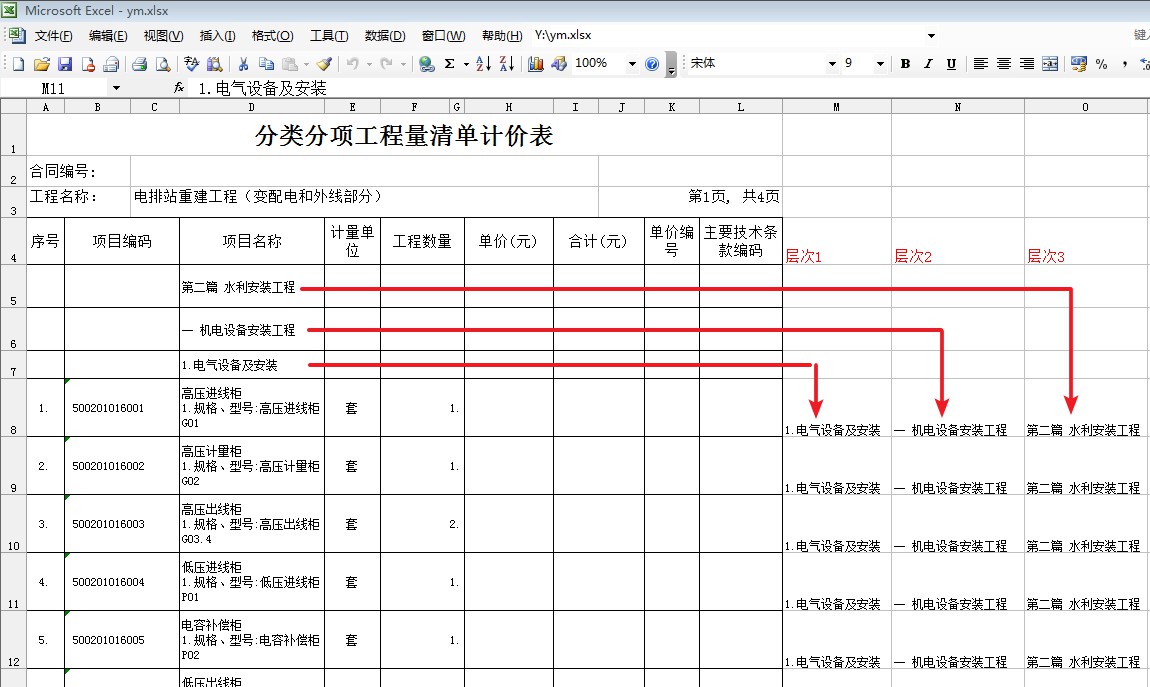
ЪЕМЪгІИУвВВЛФбЃЌжївЊЪЧЖдетжжБэИёЕФДІРэЪьЯЄГЬЖШВЛЭЌЖјвбЁЃгУЪжЙЄЕФЗНЪНЃЌЛљБОжЊЕРШчКЮДІРэГіРДЃЌВЛЛсаДЭъећЕФНХБОЁЃ
ЯЃЭћЕУЕНФуЕФжИЕуЁЃ
- import pandas as pd
- import re
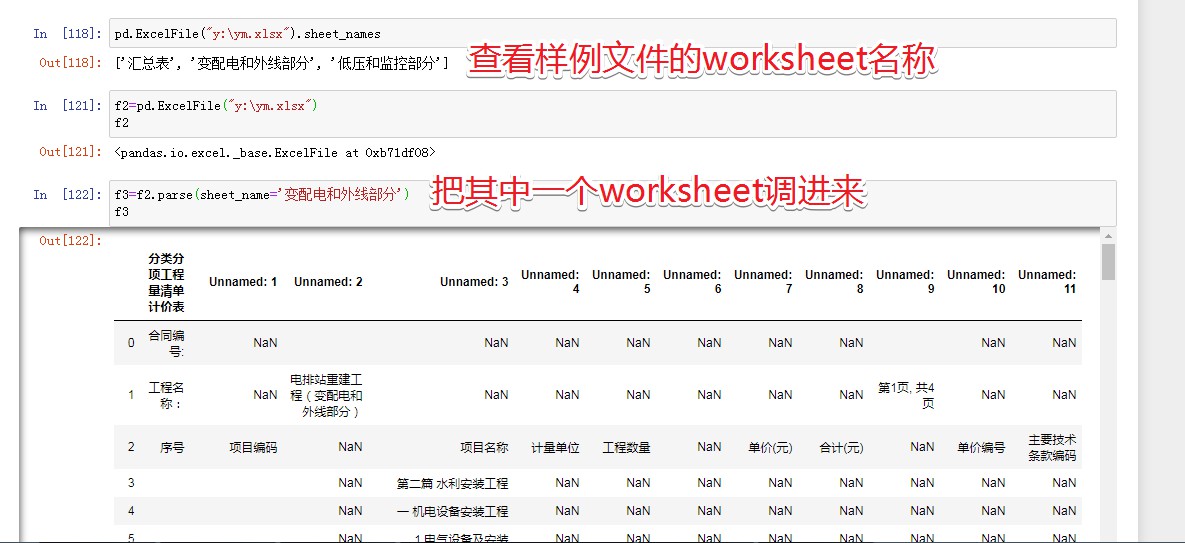
- pd.ExcelFile("y:\ym.xlsx").sheet_names #ЕУЕНsheetnames:['ЛузмБэ', 'БфХфЕчКЭЭтЯпВПЗж', 'ЕЭбЙКЭМрПиВПЗж']
- f2=pd.ExcelFile("y:\ym.xlsx")
- f3=f2.parse(sheet_name='БфХфЕчКЭЭтЯпВПЗж') #ЕМШывЛеХБэ
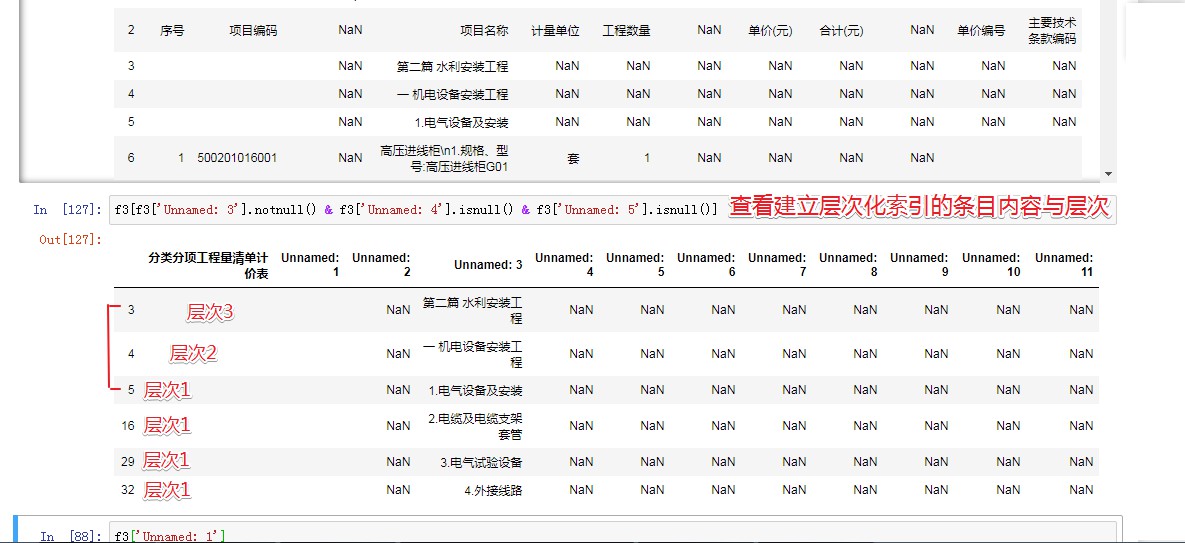
- f3[f3['Unnamed: 3'].notnull() & f3['Unnamed: 4'].isnull() & f3['Unnamed: 5'].isnull()] #ЙлВьКѓевЕНКЌгаЁОЗжзщ/ЗжМЖБъЬтЁПЕФаа
- f3.drop(f3[f3['ЗжРрЗжЯюЙЄГЬСПЧхЕЅМЦМлБэ'].isin(['КЯЭЌБрКХ:','ЙЄГЬУћГЦЃК'])].index,inplace=True) #ЩОГ§ЖрграаЃЌетжЛЪЧвЛжжР§згЕФзДЬЌЃЌЛЙгаЦфЫћМИжжПЩЩОГ§зДЬЌЃЌНјааЧхЯДЁЃ
- f3['s1']=None #Ек1МЖЗжзщБъЬтСаГѕЪМЛЏ
- f3['s2']=None #Ек2МЖЗжзщБъЬтСаГѕЪМЛЏ
- f3['s3']=None #Ек3МЖЗжзщБъЬтСаГѕЪМЛЏ
- f3.loc[f3['Unnamed: 3'].str.contains('\d\.') & f3['Unnamed: 4'].isnull() ,'s1']=f3['Unnamed: 3'] #ЮЊЕк1МЖЗжзщБъЬтСаЃЌАДЯргІБъЬтЮЛжУНјааИГжЕЁЃ
- f3.loc[:,'s1']=f3['s1'].fillna(method='ffill') #ЮЊЕк1МЖЗжзщБъЬтСаЃЌАДЯргІБъЬтЃЌЖдБОМЖПежЕЃЌгУЁОforward fillЁПЗНЪННјааИГжЕ
- f3.loc[f3['Unnamed: 3'].str.contains('^вЛ|^Жў') & f3['Unnamed: 4'].isnull() ,'s2']=f3['Unnamed: 3'] #ЮЊЕк2МЖЗжзщБъЬтСаЃЌАДЯргІБъЬтЮЛжУНјааИГжЕЁЃ
- f3.loc[:,'s2']=f3['s2'].fillna(method='ffill') #ЮЊЕк2МЖЗжзщБъЬтСаЃЌАДЯргІБъЬтЃЌЖдБОМЖПежЕЃЌгУЁОforward fillЁПЗНЪННјааИГжЕ
- f3.loc[f3['Unnamed: 3'].str.contains('^ЕквЛ|^ЕкЖў') & f3['Unnamed: 4'].isnull() ,'s3']=f3['Unnamed: 3'] #ЮЊЕк3МЖЗжзщБъЬтСаЃЌАДЯргІБъЬтЮЛжУНјааИГжЕЁЃ
- f3.loc[:,'s3']=f3['s3'].fillna(method='ffill') #ЮЊЕк3МЖЗжзщБъЬтСаЃЌАДЯргІБъЬтЃЌЖдБОМЖПежЕЃЌгУЁОforward fillЁПЗНЪННјааИГжЕ
- f3.drop(f3[f3['Unnamed: 3'].notnull() & f3['Unnamed: 4'].isnull()].index,inplace=True) #АбЁОНіЁПКЌгаЁОЗжзщ/ЗжМЖБъЬтЁПЕФааЃЌЖјЮоЪ§ОнФкШнааЃЌЩОГ§
- f3.head(8)
|
|
 ( дСICPБИ18085999КХ-1 | дСЙЋЭјАВБИ 44051102000585КХ)
( дСICPБИ18085999КХ-1 | дСЙЋЭјАВБИ 44051102000585КХ)

 ЙЗзаПЈ
ЙЗзаПЈ ЗЂБэгк 2020-12-10 00:45:01
ЗЂБэгк 2020-12-10 00:45:01
 жУЖЅПЈ
жУЖЅПЈ ЧЇНяЖЅ
ЧЇНяЖЅ ЯдЩэПЈ
ЯдЩэПЈ ТЅжї
ТЅжї