|
|

楼主 |
发表于 2020-12-12 21:23:48
|
显示全部楼层
实际应该也不难,主要是对这种表格的处理熟悉程度不同而已。用手工的方式,基本知道如何处理出来,不会写完整的脚本。
希望得到你的指点。
- import pandas as pd
- import re
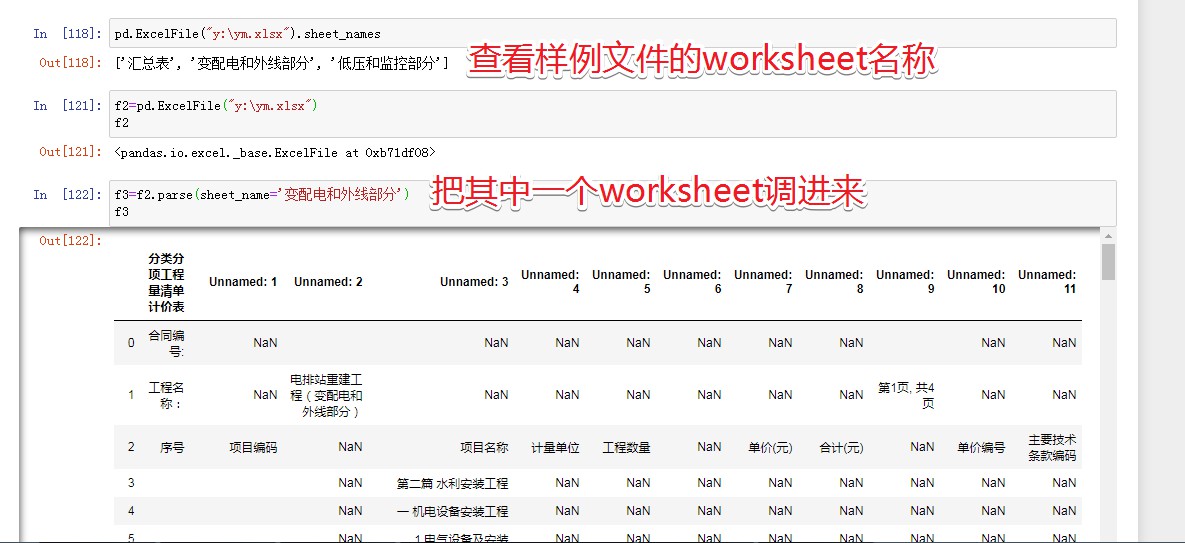
- pd.ExcelFile("y:\ym.xlsx").sheet_names #得到sheetnames:['汇总表', '变配电和外线部分', '低压和监控部分']
- f2=pd.ExcelFile("y:\ym.xlsx")
- f3=f2.parse(sheet_name='变配电和外线部分') #导入一张表
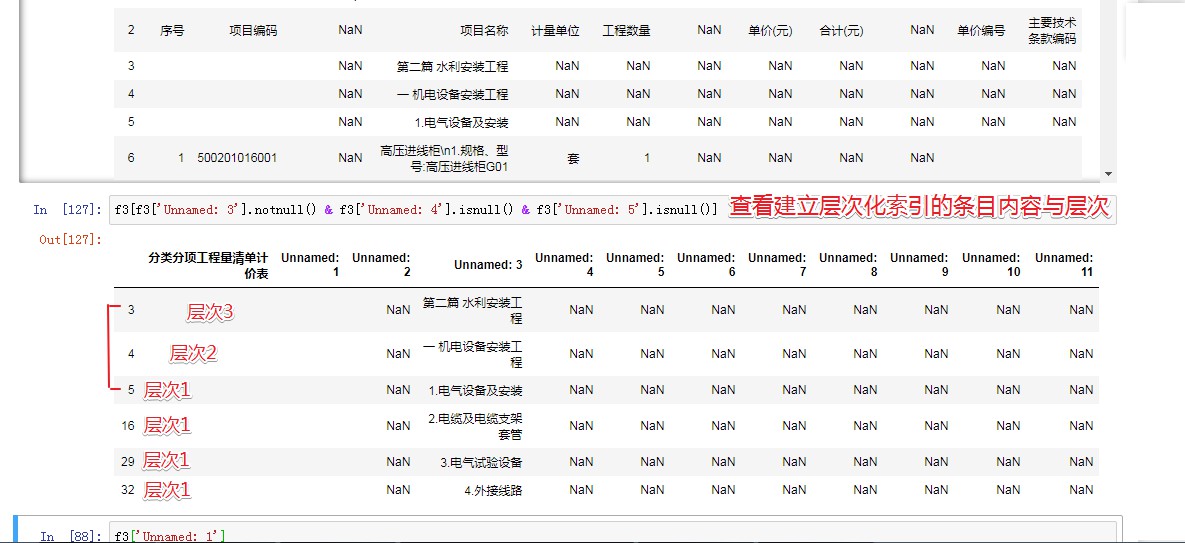
- f3[f3['Unnamed: 3'].notnull() & f3['Unnamed: 4'].isnull() & f3['Unnamed: 5'].isnull()] #观察后找到含有【分组/分级标题】的行
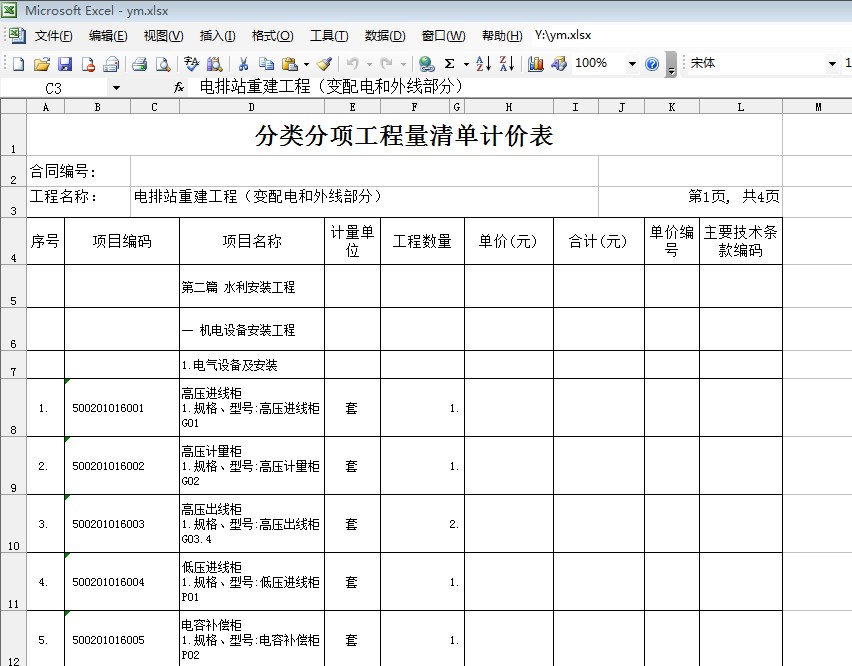
- f3.drop(f3[f3['分类分项工程量清单计价表'].isin(['合同编号:','工程名称:'])].index,inplace=True) #删除多余行,这只是一种例子的状态,还有其他几种可删除状态,进行清洗。
- f3['s1']=None #第1级分组标题列初始化
- f3['s2']=None #第2级分组标题列初始化
- f3['s3']=None #第3级分组标题列初始化
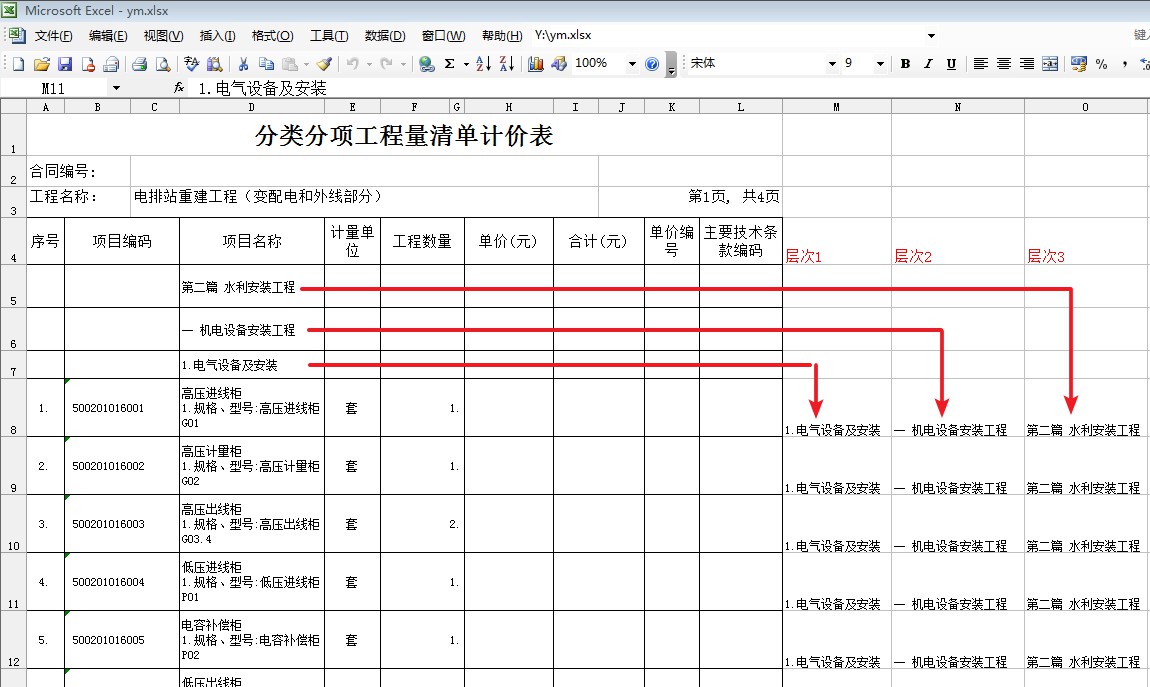
- f3.loc[f3['Unnamed: 3'].str.contains('\d\.') & f3['Unnamed: 4'].isnull() ,'s1']=f3['Unnamed: 3'] #为第1级分组标题列,按相应标题位置进行赋值。
- f3.loc[:,'s1']=f3['s1'].fillna(method='ffill') #为第1级分组标题列,按相应标题,对本级空值,用【forward fill】方式进行赋值
- f3.loc[f3['Unnamed: 3'].str.contains('^一|^二') & f3['Unnamed: 4'].isnull() ,'s2']=f3['Unnamed: 3'] #为第2级分组标题列,按相应标题位置进行赋值。
- f3.loc[:,'s2']=f3['s2'].fillna(method='ffill') #为第2级分组标题列,按相应标题,对本级空值,用【forward fill】方式进行赋值
- f3.loc[f3['Unnamed: 3'].str.contains('^第一|^第二') & f3['Unnamed: 4'].isnull() ,'s3']=f3['Unnamed: 3'] #为第3级分组标题列,按相应标题位置进行赋值。
- f3.loc[:,'s3']=f3['s3'].fillna(method='ffill') #为第3级分组标题列,按相应标题,对本级空值,用【forward fill】方式进行赋值
- f3.drop(f3[f3['Unnamed: 3'].notnull() & f3['Unnamed: 4'].isnull()].index,inplace=True) #把【仅】含有【分组/分级标题】的行,而无数据内容行,删除
- f3.head(8)
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-12-10 00:45:01
发表于 2020-12-10 00:45:01
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡