测试题:
0. 服务器是如何识访问来自浏览器还是非浏览器的?
答:通过request headers里面的 User-Agent信息进行识别的
1. 明明代码跟视频中的栗子一样,一运行却出错了,但在不修改代码的情况下再次尝试运行却又变好了,这是为什么呢?
答:重新运行加载。
2. Request 是由客户端发出还是由服务端发出?
答:客户端
3. 请问如何为一个 Request 对象动态的添加 headers?
答:使用addheaders[('User-Agent','***')]
4. 简单来说,代理服务器是如何工作的?他有时为何不工作了?
答:使用代理服务器的IP访问对应网络,并把访问的网络数据转发回本地。可能是IP连不上。
5. HTTP 有好几种方法(GET,POST,PUT,HEAD,DELETE,OPTIONS,CONNECT),请问你如何晓得 Python 是使用哪种方法访问服务器呢?
答:使用request.ProxyHandler进行设定
6. 上一节课后题中有涉及到登陆问题,辣么,你还记得服务器是通过什么来确定你是登陆还是没登陆的么?他会持续到什么时候呢?
小甲鱼打算在这里先给大家介绍一个
压箱底的模块 —— Beautiful Soup 4
翻译过来名字有点诡异:漂亮的汤?美味的鸡汤?呃
好吧,只要你写出一个普罗大众都喜欢的模块,你管它叫“Beautiful Shit”大家也是能接受的……

Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup 会帮你节省数小时甚至数天的工作时间。
这玩意儿到底怎么用?
看这 -> 传送门上边链接是官方的快速入门教程(不用惧怕,这次有中文版了),请大家花差不多半个小时的时间自学一下,然后完成下边题目。
_噢,对了,大家可以使用 pip 安装(Python3.4 以上自带的神一般的软件包管理系统,有了它 Python 的模块安装、卸载全部一键搞定!
打开命令行窗口(CMD) -> 输入 py -3 -m pip install BeautifulSoup4 命令 -> 搞定:

No step two!!!
答:
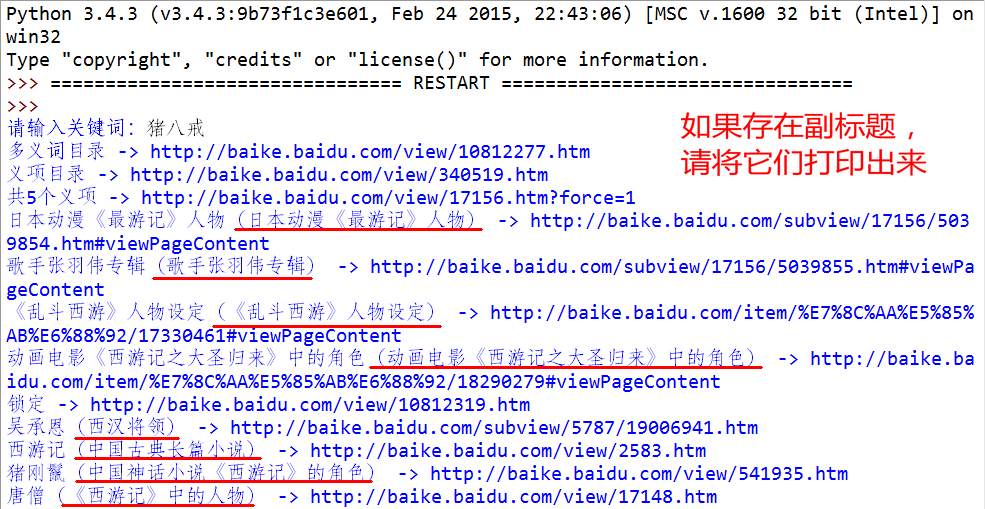
1. 直接打印词条名和链接不算什么真本事儿,这题要求你的爬虫允许用户输入搜索的关键词。
然后爬虫进入每一个词条,然后检测该词条是否具有副标题(比如搜索“猪八戒”,副标题就是“(中国神话小说《西游记》的角色)”),如果有,请将副标题一并打印出来:
程序实现效果如下:
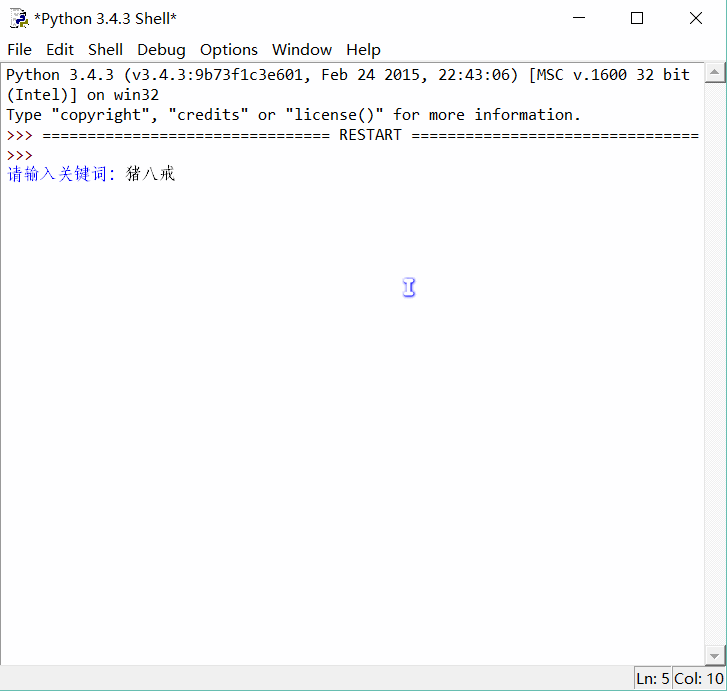
2. 哗啦啦地丢一堆链接给用户可不是什么好的体验,我们应该先打印 10 个链接,然后问下用户“您还往下看吗?”
来,我给大家演示下:
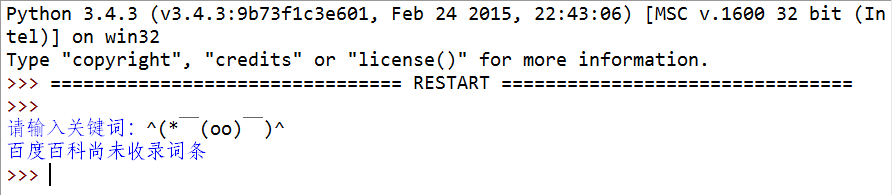
然后为了增加用户体验,代码需要捕获未收录的词条,并提示:
提示:希望你还记得有
生成器这么个东东









 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)



