|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
本帖最后由 id是什么 于 2018-7-4 17:08 编辑
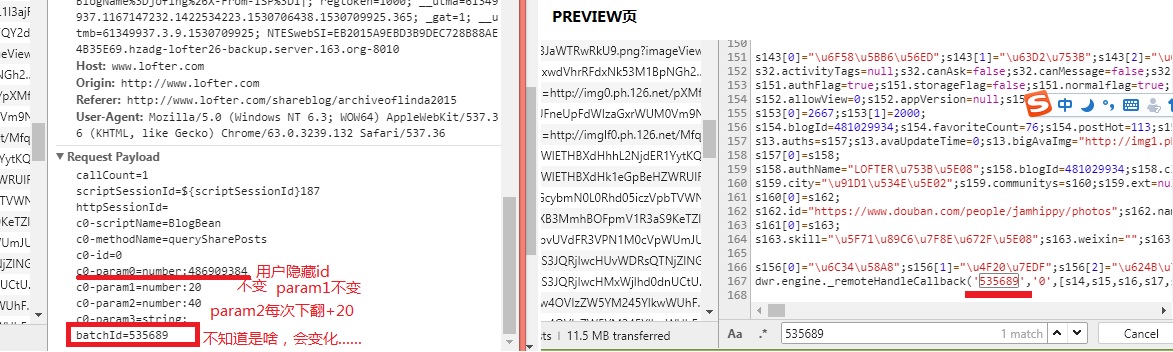
作为lofter的忠实用户,我尝试收集的是lofter的推荐页面,一个不需要登录就可以查看的页面。
(其实我更想收集自己的lofter的喜欢页面,我已经喜欢了几千张图了。但是进入这个页面需要登录,登录又需要验证,我毫无思路)
总之,页面地址如下,以用户“老相册”的推荐地址为例:http://www.lofter.com/shareblog/vintagephotos
我遇到的问题是:
这个页面只显示前20条推荐(每条推荐内含0~9张图不等),必须PgDn不断下翻,而且下翻看起来永无止尽,我怀疑它只有这一页……
而我不会用我的python下翻,或者做出其他动作获取其余部分的html代码。
附上我目前写的代码(只能抓取前20条的版本)
如果您留意到了我其他方面的错误和可以改进之处(我隐隐约约感觉找url那里可以靠标签精确找出来的),欢迎告诉我,将会非常感谢!
import requests
from bs4 import BeautifulSoup
import re
import os
import urllib.request
agent="Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
#根据lofter用户id创建文件夹
authorid =str(input("输入用户名"))
res = requests.get("http://www.lofter.com/shareblog/%s"%authorid)
soup = BeautifulSoup(res.text,"html.parser")
filepath = r'F:/0music/%s/'%authorid
if os.path.exists(filepath) == False:
os.makedirs(filepath)
#查找URL链接,列表去重
pattern = re.compile('http://.*?\.jpg')
targets = soup.find_all("div",class_="img")
urls0 = pattern.findall(str(targets))
urls = list(set(urls0))
#下载到本地
for each in urls:
print(each)
getImg(each)
def getImg(url):
localpath = os.path.join(filepath,"%s"%url.split('/')[-1])
urllib.request.urlretrieve(url,localpath)
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2018-7-4 16:58:55
发表于 2018-7-4 16:58:55
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 楼主
楼主