|
|
БОЬћзюКѓгЩ suchocolate гк 2020-2-8 21:37 БрМ
НјНзДјЗвыАц
fy

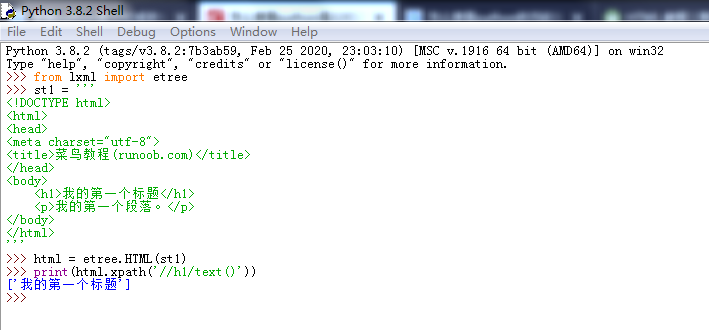
- from urllib import request, parse
- from urllib.parse import quote
- from lxml import etree
- from tkinter import *
- import json
- # гЂЮФЕЅДЪВщбЏЭјжЗ
- ebase = 'http://dict.youdao.com/w/eng/'
- # жаЮФЕЅДЪВщбЏЭјжЗ
- cbase = 'http://dict.youdao.com/w/'
- # ЗвыЭјжЗ
- trans = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
- # ВщбЏЪБhttpЭЗ
- headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"}
- # ЗвыЬсНЛЕФзжЕф
- dic = {"doctype": "json"}
- # ХаЖЯВщбЏРраЭ
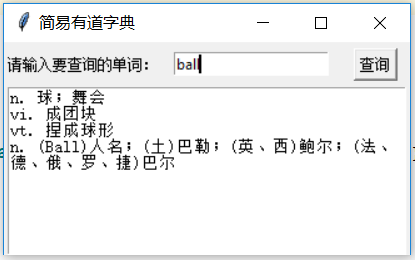
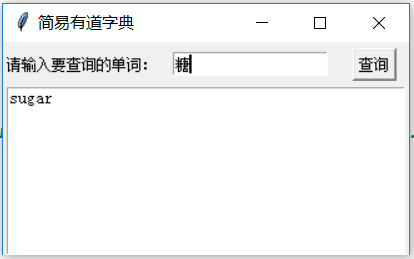
- def chaxun():
- if v.get() == 1:
- chaci()
- else:
- fanyi()
- # ВщДЪ chaci():
- def chaci():
- wd = e1.get()
- if '\u4e00' <= wd <= '\u9fff':
- # ШчЙћЪЧжаЮФВщбЏЃЌзЊЛЛжаЮФЮЊURLБрТыИёЪН
- wd = quote(wd)
- url = cbase + wd
- q = request.Request(url=url, headers=headers)
- r = request.urlopen(q, timeout=2)
- html = etree.HTML(r.read().decode('utf-8'))
- result = html.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/div[1]/div/ul/p/span/a/text()')
- else:
- url = ebase + wd
- q = request.Request(url=url, headers=headers)
- r = request.urlopen(q, timeout=2)
- html = etree.HTML(r.read().decode('utf-8'))
- result = html.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/div[1]/div/ul/li/text()')
- # ЧхРэtextЃЌжиаТЯдЪО
- text1.delete(1.0, END)
- # ШчЙћгаНсЙћЃЌЯдЪОНсЙћ
- if len(result) != 0:
- for pt in result:
- text1.insert(INSERT, pt + '\n')
- else:
- # ШчЙћУЛгаНсЙћЃЌЬсЪОУЛгаНсЙћ
- text1.insert(INSERT, 'There is no explain.')
- # Звы
- def fanyi():
- text1.delete(1.0, END)
- wd = e1.get()
- dic['i'] = wd
- data = bytes(parse.urlencode(dic), encoding='utf-8')
- q = request.Request(url=trans, data=data, headers=headers, method='POST')
- r = request.urlopen(q)
- result = json.loads(r.read().decode('utf-8'))
- text1.insert(INSERT, result['translateResult'][0][0]['tgt'])
- if __name__ == '__main__':
- # жїКЏЪ§ЃЌЖЈвхвЛИіtkЖдЯѓ
- root = Tk()
- root.title('МђвзгаЕРзжЕф')
- l1 = Label(root, text='ЧыЪфШывЊВщбЏЕФФкШнЃК')
- l1.grid(row=0, column=0)
- e1 = Entry(root)
- e1.grid(row=0, column=1, padx=1, pady=5)
- bt1 = Button(root, text='ВщбЏ', command=chaxun)
- bt1.grid(row=0, column=2, padx=5, pady=5)
- text1 = Text(root, width=59, height=10)
- text1.grid(row=1, columnspan=5, padx=5, pady=7)
- v = IntVar()
- v.set(1)
- Radiobutton(root, text="ВщДЪ", variable=v, value=1).grid(row=0, column=3)
- Radiobutton(root, text="Звы", variable=v, value=2).grid(row=0, column=4)
- mainloop()
|
|
 ( дСICPБИ18085999КХ-1 | дСЙЋЭјАВБИ 44051102000585КХ)
( дСICPБИ18085999КХ-1 | дСЙЋЭјАВБИ 44051102000585КХ)

 ЙЗзаПЈ
ЙЗзаПЈ ЗЂБэгк 2020-2-8 18:21:00
ЗЂБэгк 2020-2-8 18:21:00
 жУЖЅПЈ
жУЖЅПЈ ЧЇНяЖЅ
ЧЇНяЖЅ ЯдЩэПЈ
ЯдЩэПЈ
 ТЅжї
ТЅжї ЗЂБэгк 2020-3-21 14:53:59
ЗЂБэгк 2020-3-21 14:53:59