|
|
 发表于 2020-3-18 15:32:24
|
显示全部楼层
发表于 2020-3-18 15:32:24
|
显示全部楼层
Python 爬取文章【代码+详解】
emm,老师叫我们阅读,看看手里的钱,再看看微信支付宝。。。还是爬吧
看了半天百度,最后还是选择轩宇阅读网
为什么?
因为好爬啊 
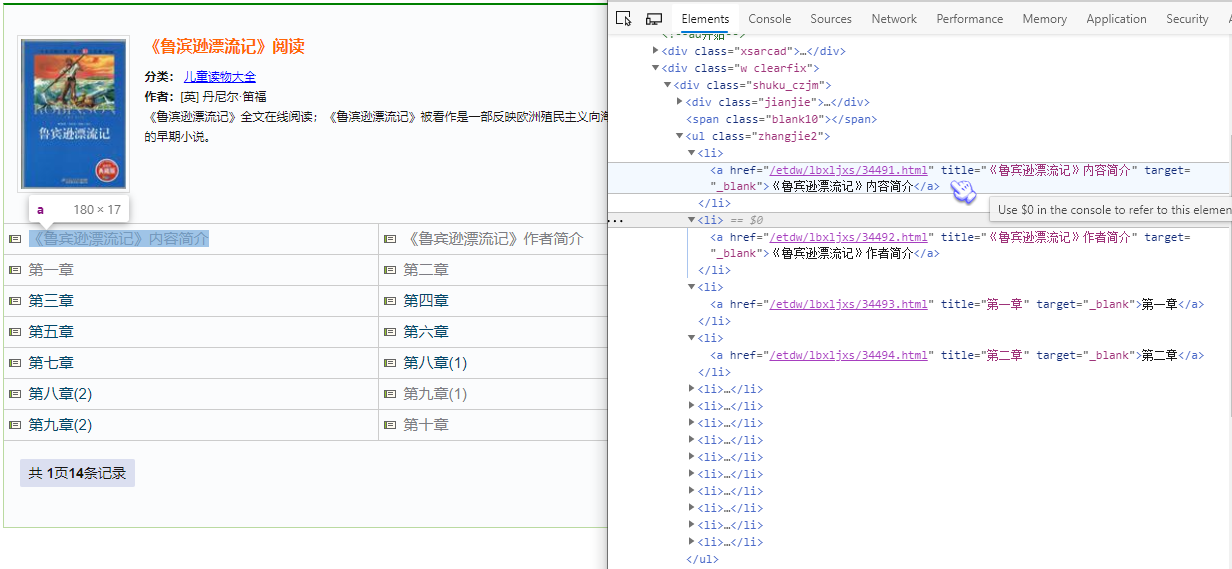
先看看文章页
示例页
惊 Σ(っ °Д °;)っ,这么好爬! Σ(っ °Д °;)っ,这么好爬!
赶紧定义一个爬取章节的函数 getChapter:
- from requests import get #导入requests的get ,爬取页面用
- from bs4 import BeautifulSoup as BS #导入bs4的BeautifulSoup并命名为BS ,解析页面用
- def getChapter(url):
- """
- 获取章节url
- 参数说明:
- url:文章链接(字符串)
- 返回说明:
- (标题(字符串),链接(列表))
- """
- urls = [] #初始化存放链接的列表
- res = get(url) #爬取页面
- res.encoding = 'gb2312' #设置编码,不然会乱码
- soup = BS(res.text, 'html.parser') #设置网页解析
- for each in soup.find('ul', class_='zhangjie2').findAll('li'):#用each取查找class为zhangjie2的ul里的li的列表
- urls.append('https://www.xyyuedu.com'+each.a['href']) #获取链接
- return soup.h1.text[:-2], urls #返回链接及标题
章节爬完了,开始爬页数
有的只有一页,有的有很多页
根据上面的两张图,我们发现:
1.只有一页的的只有ul,没有li,有多页的既有ul,也有li。
2.第一页为https://www.xyyuedu.com/etdw/lbxljxs/34493.html,其他页为https://www.xyyuedu.com/etdw/lbxljxs/34493_页数.html。
根据规律,我们可以写出提取页数程序 getPages:
- def getPages(urls):
- """
- 获取章节页数(批量)
- 参数说明:
- urls:要获取的链接(批量)(列表)
- 返回说明:
- 链接(列表)
- """
- Urls = [] #初始化存放链接的列表
- for eachUrl in urls: #用eachUrl取每个链接
- Urls.append(eachUrl) #添加此链接(第一页)
- soup = BS(get(eachUrl).text, 'html.parser') #爬取页面并设置网页解析
- li = soup.find('div', class_='list-pages page-center').findAll('li') #获取页数表
- if li == []: #如果为空(只有第一页)
- continue #跳过本次循环,继续下一轮循环
- pages = int(li[len(li)-2].a.text) #获取总页数
- for page in range(2, pages+1): #根据规律循环页数
- Urls.append(eachUrl[:-5]+'_'+str(page)+'.html') #根据规律添加链接
- return Urls #返回链接
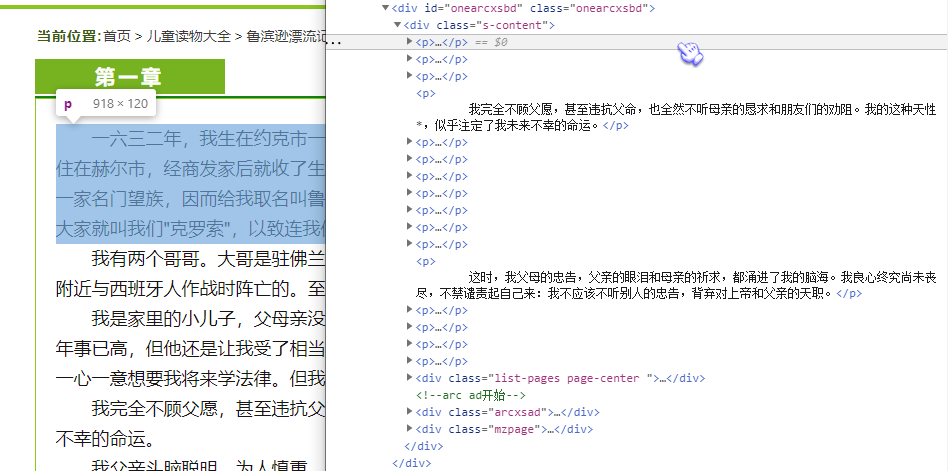
接下来,就是获取内容了
太简单了,内容都在p里面
- def getText(urls):
- """
- 获取文字(批量)
- 参数说明:
- urls:要获取的链接(批量)(列表)
- 返回说明:
- 文字(列表)
- """
- allText = [] #初始化存放文字的列表
- for eachUrl in urls: #用eachUrl循环每个链接
- text = [] #初始化本页存放文字的列表
- res = get(eachUrl) #爬取页面
- res.encoding = 'gb2312' #设置编码,不然会乱码
- soup = BS(res.text, 'lxml') #设置网页解析(由于网页不标准,所以要用lxml作为解析器)
- for p in soup.find('div', id="onearcxsbd").findAll('p'): #用each取查找id为arcxsbd的div里的p标签的列表
- p = p.text #提取文字
- p = p.replace('\n', '') #过滤换行符(\n)
- p = p.replace('\t', '') #过滤tab(\t)
- p = p.replace('\u3000', '') #过滤不知道是说明符号的符号
- if not(p == '' or p.isspace()): #如果不是空行
- text.append(p) #添加文字到列表
- allText.append([soup.h1.text, text]) #添加本章节名和文字到文字列表
- return allText #返回文字列表
需要注意的是,BeautifulSoup时解析器要写lxml,因为网页不标准
最后,来定义一个写入docx的方法:
- def writeDocx(title, text):
- """
- 写入文档
- 参数说明:
- title:标题
- text:文字
- 返回说明:
- 无
- """
- doc = Document() #实例化一个文档
- doc.styles['Normal'].font.name=u'微软雅黑' #设置字体名称
- doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑') #设置字体
- doc.add_heading(title, level=1) #添加标题
- for each in text: #用each取文字
- doc.add_heading(each[0], level=2) #添加小节标题
- for ph in each[1]: #用pn取文字
- doc.add_paragraph(ph) #添加段落
- doc.save(title+'.docx') #保存文档
整体就完工了
完整代码:
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-3-15 16:37:51
发表于 2020-3-15 16:37:51




 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡