|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
本帖最后由 负离负离子 于 2020-4-22 10:06 编辑
随便翻了一下前面好像没有这种
看视频的时候跟着做的
目前功能还是比较少
就是从最近更新的开始下载你想要的本子数量,可以用第二次输入的数值来进行一定程度上的控制
理论上可以加个根据输入的tag来下载特定的本子的功能
不过暂时没有什么动力去做
为了避免碰到一个长篇本子在那下个不停停滞进程
暂时一个本子只下前40页
有需要的话可以自己修改下代码
我好像没有权限用[hide]设置回复可见
版主可以设置的话能不能帮我设置一下
不行的话还是希望大家如果想测试一下代码的话随便回复点啥
给我萌新一个小小的反馈
- import os
- import re
- import sys
- import time
- import urllib.request
- def url_open(url): # 隐藏身份地打开目标url,返回未read的response
- try:
- req = urllib.request.Request(url)
- req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
- 'Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3706.400 SLBrowser/10.0.3974.400')
- response = urllib.request.urlopen(req)
- except urllib.error.HTTPError:
- if url[len(url) - 2] == 'p':
- url = url.replace('.jpg', '.png')
- else:
- url = url.replace('.png', '.jpg')
- req = urllib.request.Request(url)
- req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
- 'Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3706.400 SLBrowser/10.0.3974.400')
- response = urllib.request.urlopen(req)
- return response
- def get_start_num(url, reduced_number): # 得到第一个想要本子封面的网页序号
- html = url_open(url).read().decode('utf-8')
- pos = html.find('cover target-by-blank') - 16
- return int(html[pos:pos + 6]) - reduced_number
- def get_img_address(url, i): # 从本子首页找到本子图片的地址列表[(name,url)]
- ret = []
- name_index = 1
- html = url_open(url).read().decode('utf-8')
- start_pos = html.find('image-container')
- print(start_pos)
- while True:
- if name_index > 40: # 这里用来解除页数限制
- break
- start_pos = html.find('data-src', start_pos) + 10
- if start_pos-10 == -1:
- break
- end_pos = re.search(r'\.jpg|\.png', html[start_pos:]).end() + start_pos
- img_address = html[start_pos:end_pos]
- ret.append(('picture_' + str(name_index), img_address))
- start_pos = end_pos
- name_index += 1
- if name_index < 40:
- print('第%d本本子的图片地址已全部找到' % (i + 1))
- else:
- print('第%d本本子的图片地址可能未找齐' % (i + 1))
- return ret
- def save_img(img_address, i): # 既然知道图片地址了,呐赶快下载吧
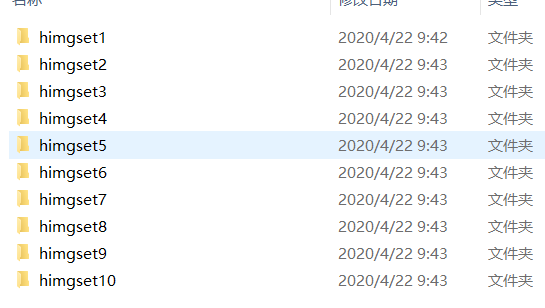
- file_name = 'himgset' + str(i + 1)
- os.mkdir(file_name)
- for each in img_address:
- response = url_open(each[1])
- img = response.read()
- with open(file_name + '\\' + str(each[0]) + '.jpg', 'wb') as image_handle:
- image_handle.write(img)
- print('第%d本本子的%s保存完成' % (i+1, each[0]))
- def download_himgs(url, max_count, reduced_number):
- set_num = get_start_num(url, reduced_number)
- for i in range(0, max_count):
- set_url = url + '/g/' + str(set_num - i) + '/list2/'
- img_address = get_img_address(set_url, i)
- if img_address == -1:
- continue
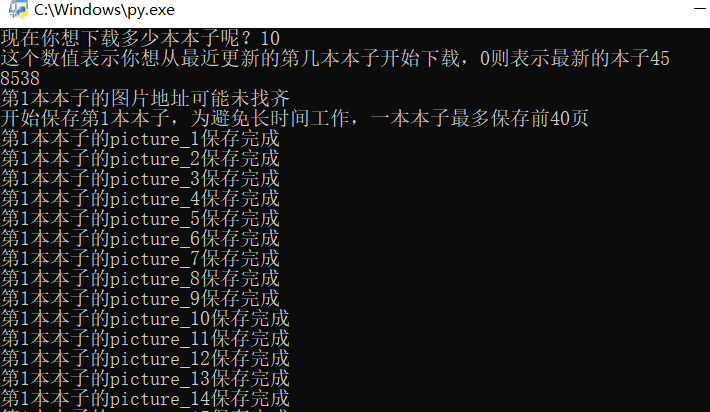
- print('开始保存第' + str(i + 1) + '本本子,为避免长时间工作,一本本子最多保存前40页')
- save_img(img_address, i)
- print('保存第' + str(i + 1) + '本本子已经完成,已完成百分之%f' % ((i + 1) / max_count * 100))
- if __name__ == '__main__':
- try:
- os.mkdir('sth_u_shall_not_see')
- except FileExistsError:
- print('已存在和欲创建文件夹相同名称的文件夹,为避免数据丢失,程序即将关闭')
- time.sleep(3)
- sys.exit()
- os.chdir('sth_u_shall_not_see')
- first_url = 'https://zh.nyahentai.cc/'
- try:
- count = int(input('现在你想下载多少本本子呢?'))
- magic_number = int(input('这个数值表示你想从最近更新的第几本本子开始下载,0则表示最新的本子'))
- if count <= 0 or magic_number < 0:
- raise ValueError
- except ValueError:
- print('输入非法')
- print('不要试图引发bug 亲爱的')
- time.sleep(3)
- sys.exit()
- download_himgs(first_url, count, magic_number)
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-4-22 10:05:31
发表于 2020-4-22 10:05:31
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡