|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
本帖最后由 xiaosi4081 于 2020-5-29 12:52 编辑
python 爬虫入门教程(1)
1.模块选择
python 爬虫可以用两个模块:urllib 和 requests
在这里,
我们使用 python 程序员都在用的requests模块。
2.开始实例
导入 requests:

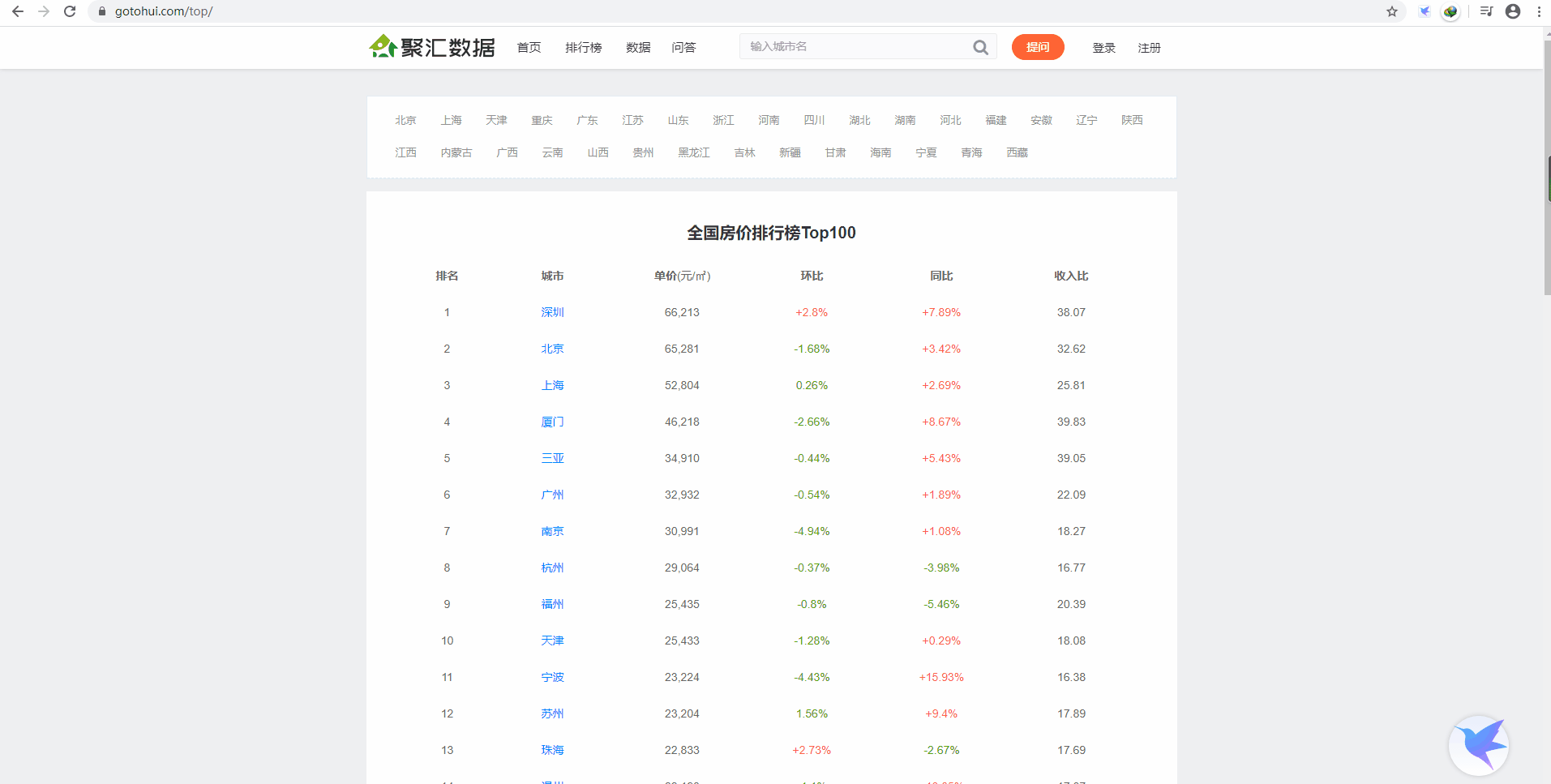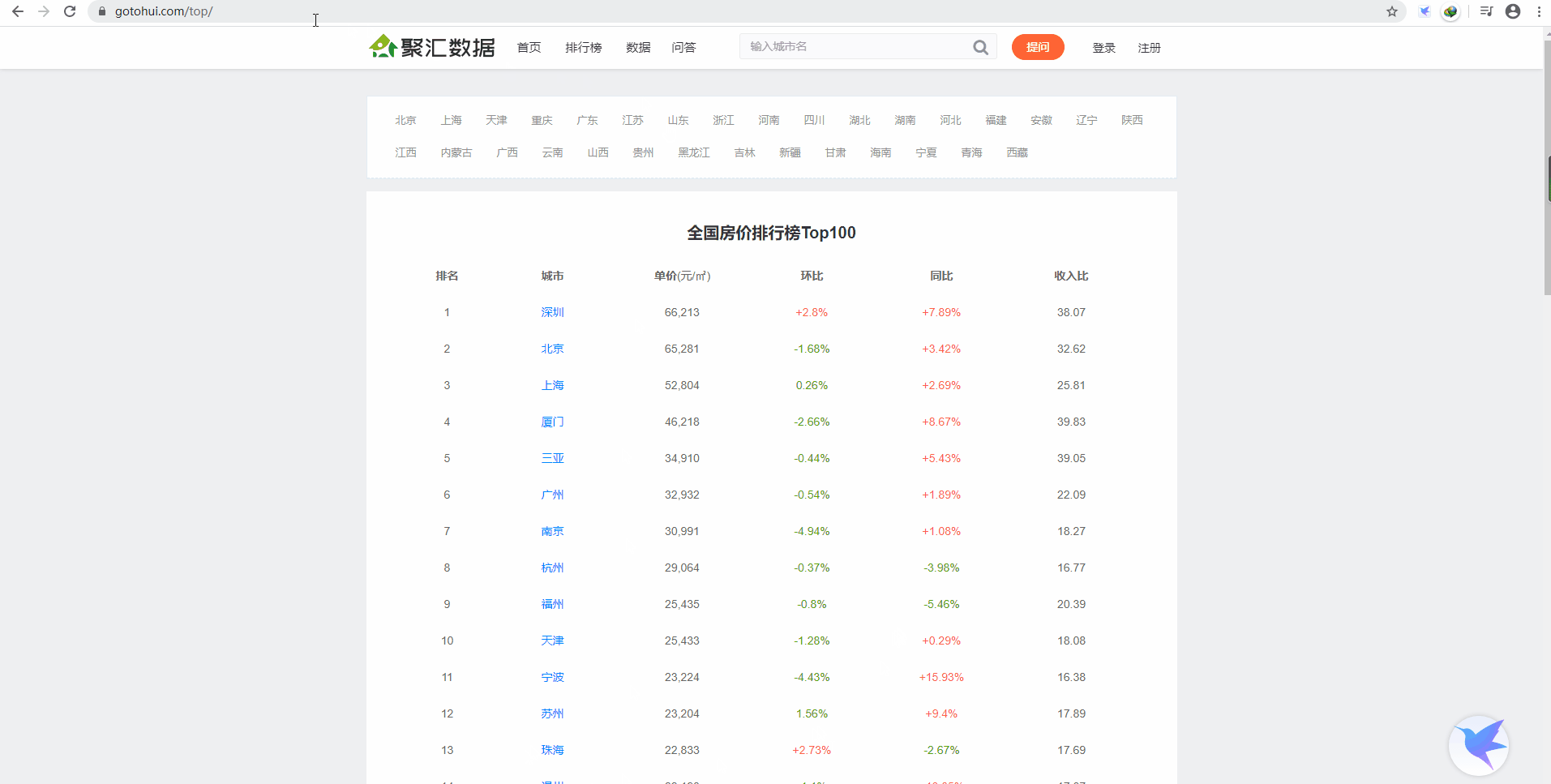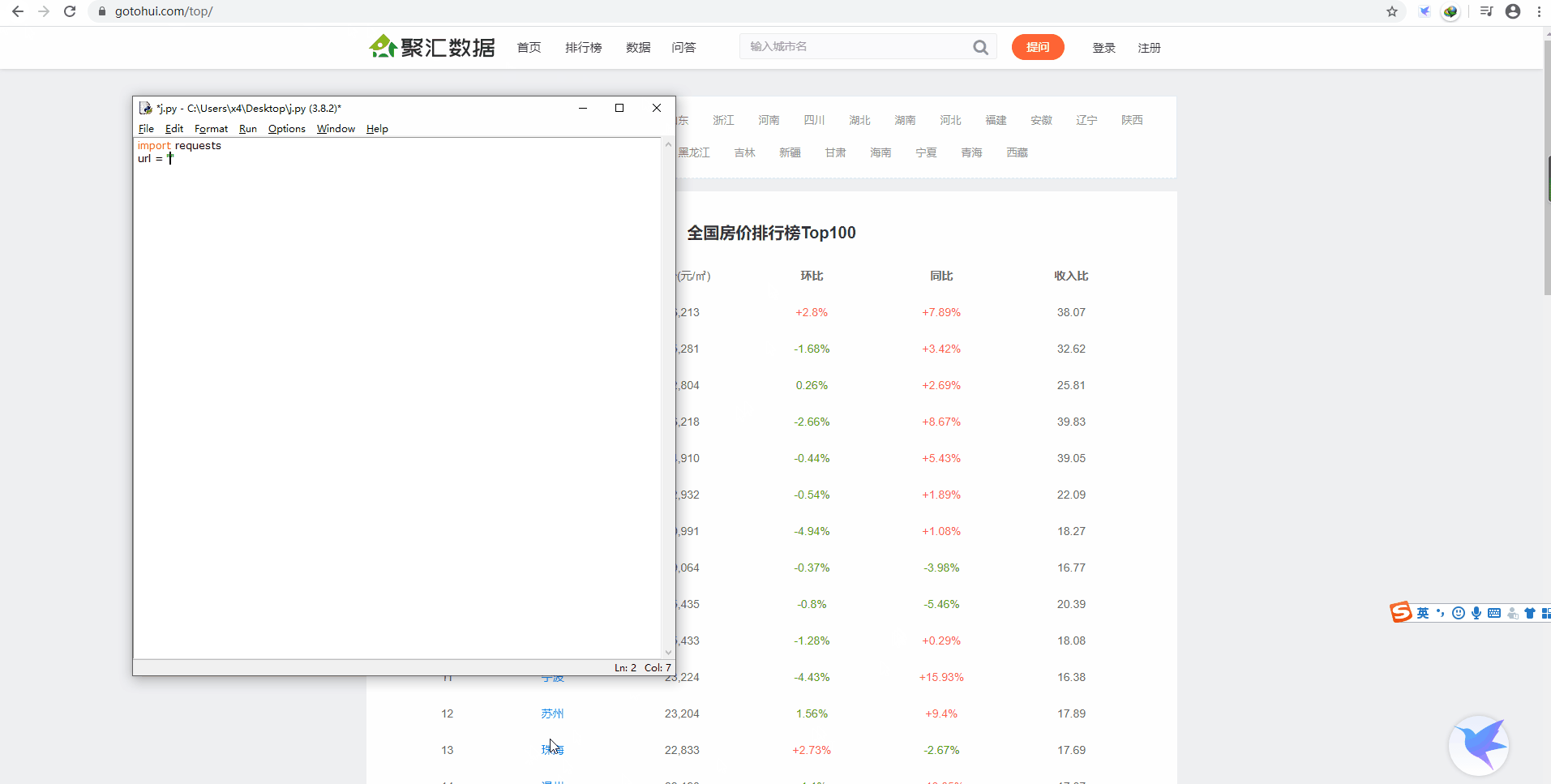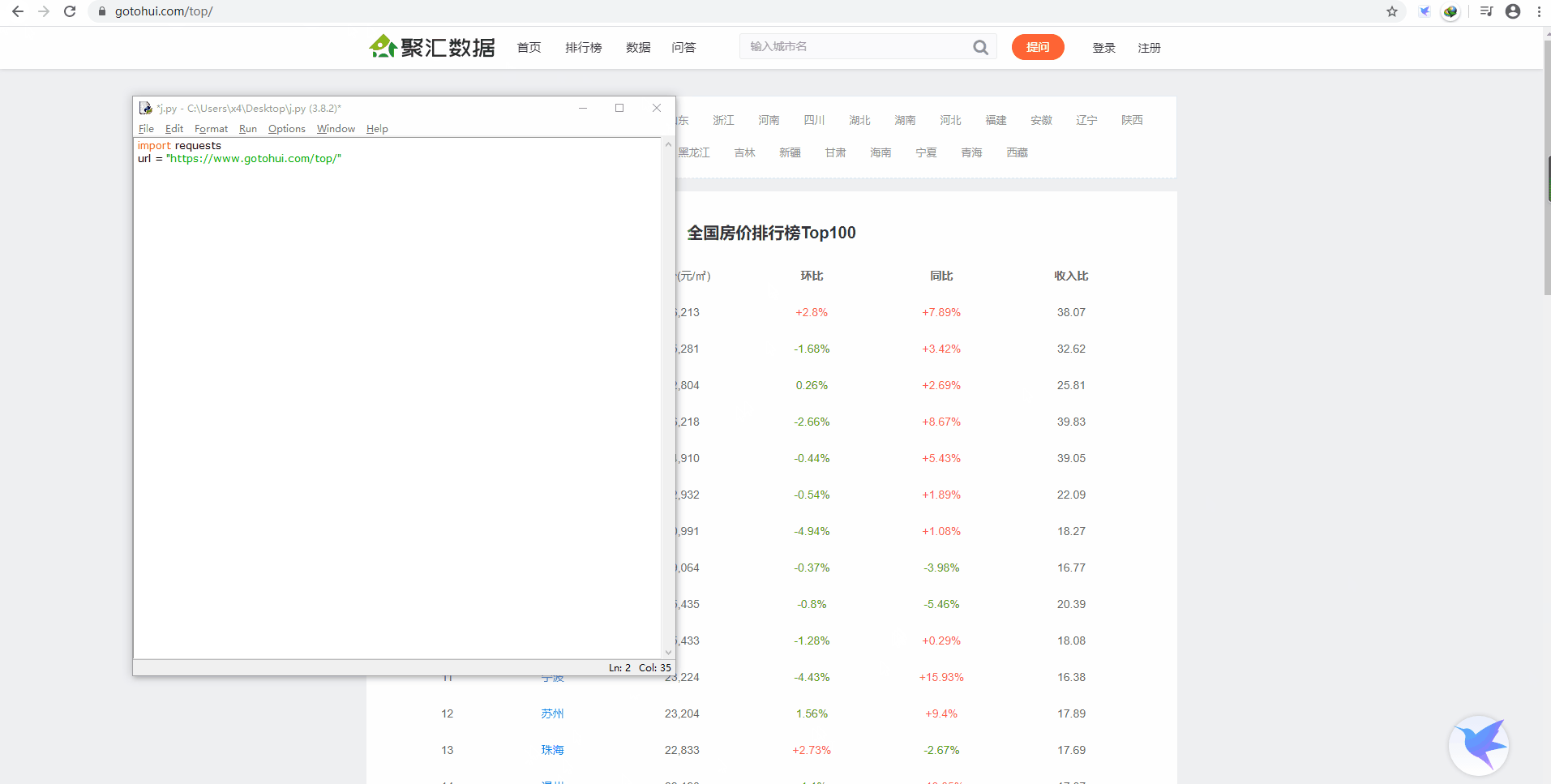
爬取房价数据
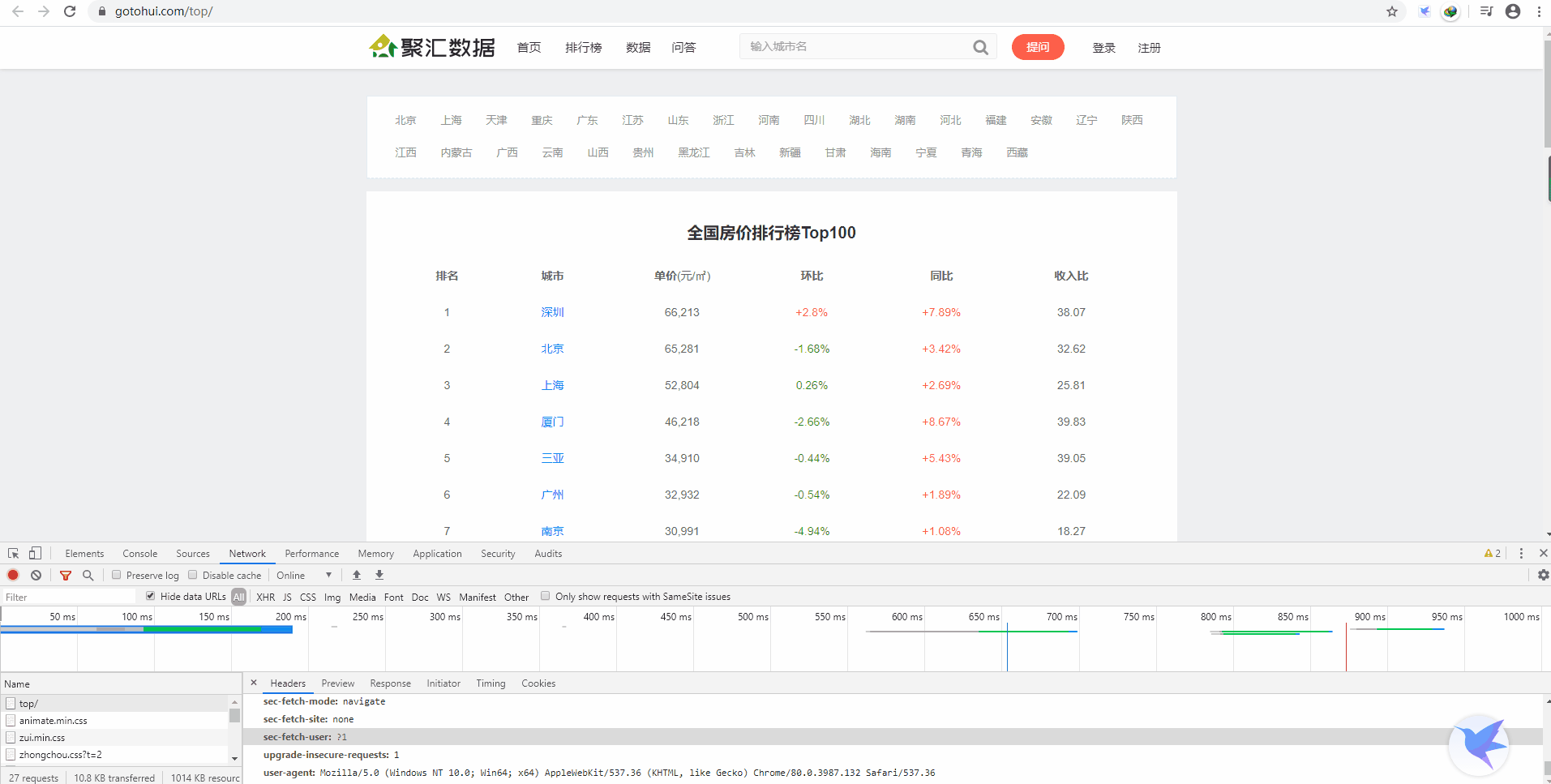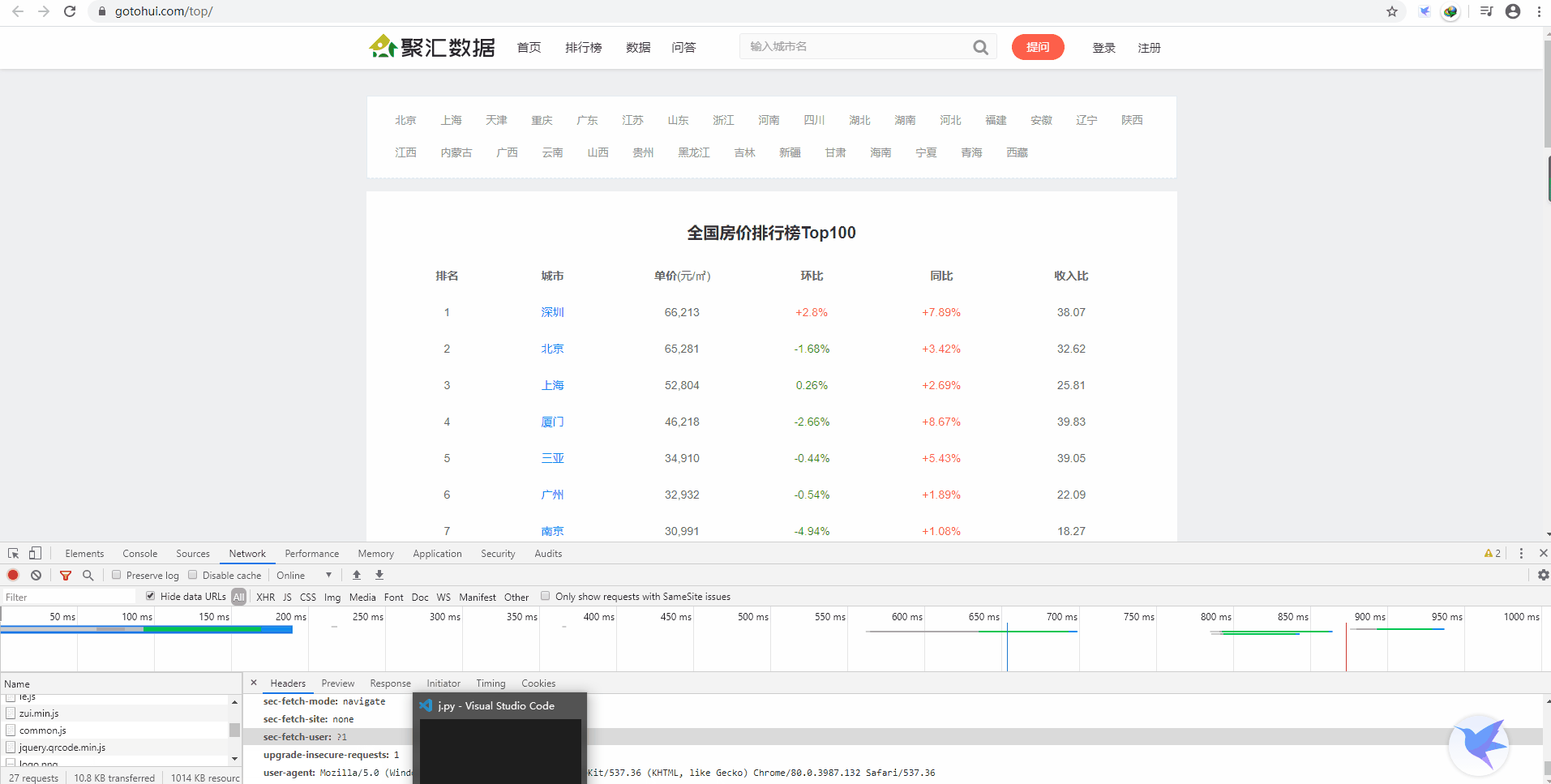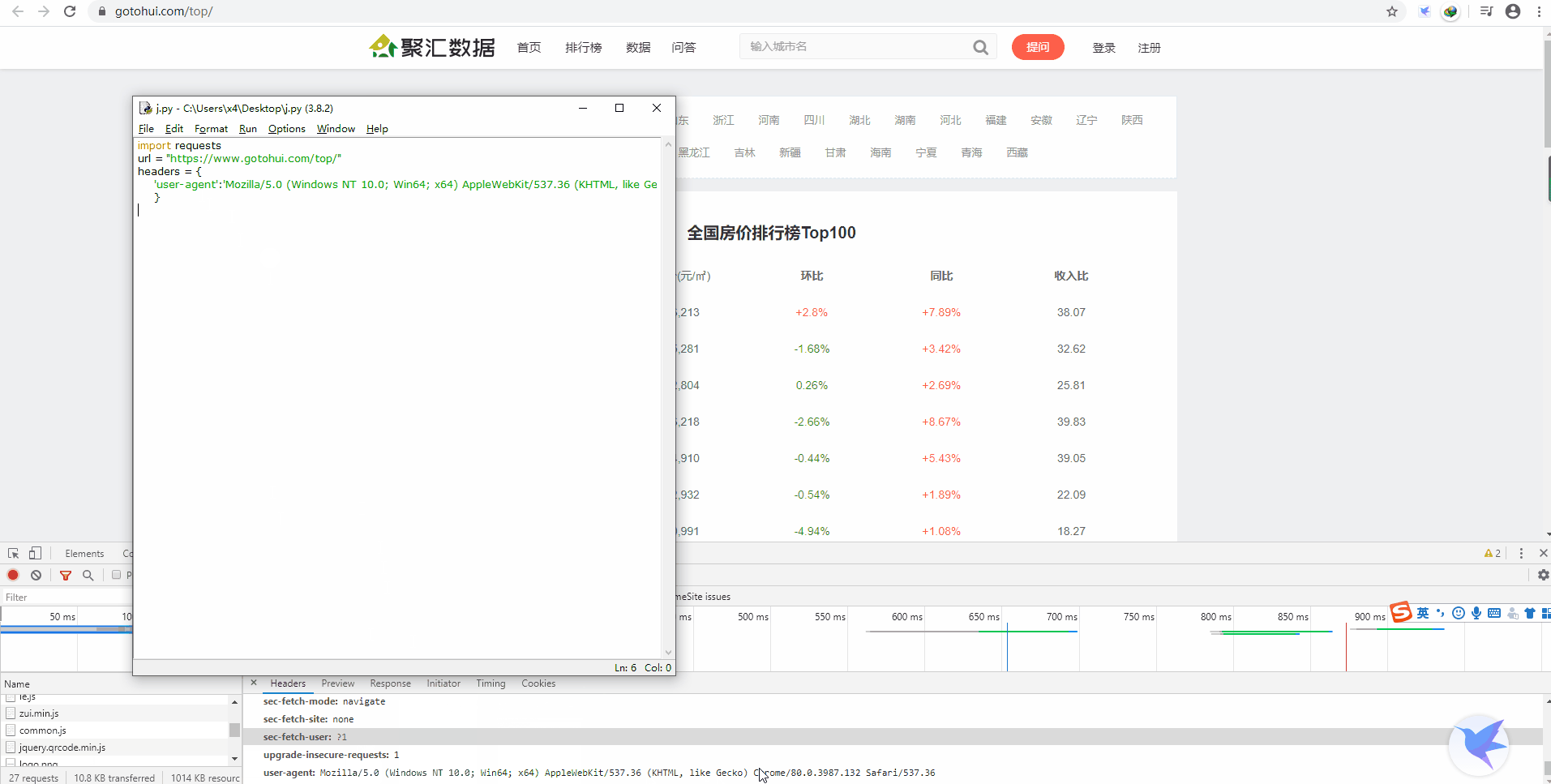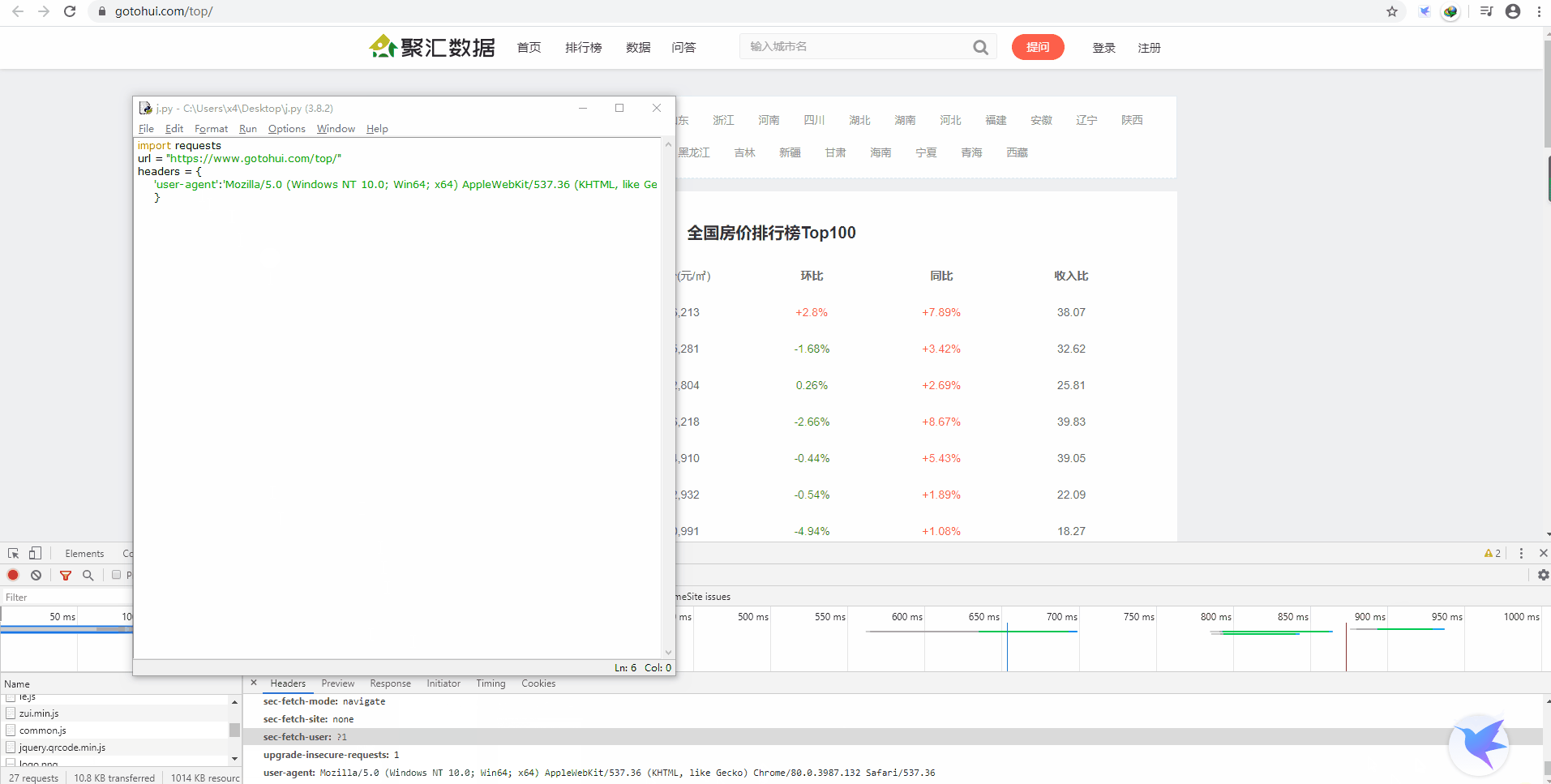
我们先新建一个变量 url,它的值就是目标网页网址:
再新建一个请求头 headers:
然后我们要用 requests 库里的 get,还要新建一个变量 res 去存储结果,代码如下:
- res = requests.get(url,headers=headers)
图:
把结果存储到 txt 文件里,如果直接在 idle 打印出来的话 ... 
存储代码如下:
- with open("test.txt",'w',encoding='utf-8') as file:
- file.write(res.text)
处理好后,运行一遍(Ctrl+f5)
我们来分析一下:
发现我们想要的数据在 table 标签里
而 table 标签里面的 class 值为 :"stable"
所以接下来我们使用 “漂亮的” BeautifulSoup 来对网页进行解析
代码如下:
- soup = BeautifulSoup(res.text,'lxml')
记得还要新建一个变量来存储结果
喂,还要在开头加上这句语句:
- from bs4 import BeautifulSoup
不然,会报错:
- soup = BeautifulSoup(res.text,'lxml')
- NameError: name 'BeautifulSoup' is not defined
很常见的错误,不是吗?
咳咳,回到正题
接下来,调用函数 find()
必须的参数:
标签名
可选的参数:
id 值
class 值
...
这里我们只需要两个参数:标签名 、class 值
代码:
- stable = soup.find("table",class_ = "stable")
ps:注意这里为了不与 class(类) 冲突,才用了 class_
然后我们提取 tr 元素:
- target = stable.find_all("tr")
接下来就是提取关键数据:
我们要用到一个东西:.next_sibling,
因为我们需要兄弟节点的值,所以用它
这边我们跳过第一行,直接开始第二行的读取:
- for each in target:
- if i != 1:
- print(each.td.next_sibling.text)
- print(each.td.next_sibling.next_sibling.text)
- i = i+1
效果:
- 深圳
- 66,213
- 北京
- 65,281
- 上海
- 52,804
- 厦门
- 46,218
- 三亚
- 34,910
- 广州
- 32,932
- 南京
- 30,991
- 杭州
- 29,064
- 福州
- 25,435
- 天津
- 25,433
- 宁波
- 23,224
- 苏州
- 23,204
- 珠海
- 22,833
- 温州
- 22,190
- 青岛
- 20,833
- 丽水
- 19,515
- 武汉
- 17,517
- 合肥
- 16,618
- 无锡
- 16,543
- 金华
- 16,447
- 东莞
- 16,130
- 济南
- 15,842
- 南通
- 15,826
- 大连
- 15,589
- 舟山
- 15,481
- 常州
- 15,408
- 成都
- 15,261
- 海口
- 15,079
- 西安
- 15,078
- 石家庄
- 15,034
- 台州
- 14,579
- 衢州
- 14,439
- 廊坊
- 14,141
- 郑州
- 14,030
- 扬州
- 13,666
- 昆明
- 13,454
- 南昌
- 13,446
- 大理
- 13,416
- 嘉兴
- 13,348
- 佛山
- 12,813
- 南宁
- 12,737
- 莆田
- 12,699
- 兰州
- 12,385
- 漳州
- 12,368
- 绍兴
- 12,232
- 重庆
- 12,182
- 唐山
- 11,999
- 泉州
- 11,964
- 太原
- 11,949
- 芜湖
- 11,884
接下来我们要把数据写入Excel表里
使用openpyxl把数据写入Excel
废话不多说,上代码:
- import requests
- from bs4 import BeautifulSoup
- import openpyxl
- url = "https://www.gotohui.com/top/"
- headers = {
- 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
- }
- res = requests.get(url,headers=headers)
- soup = BeautifulSoup(res.text,'lxml')
- stable = soup.find("table",class_ = "stable")
- target = stable.find_all("tr")
- i=1
- name=[]
- num = []
- wb = openpyxl.Workbook()
- ws = wb.active
- for each in target:
- if i != 1:
- name.append(each.td.next_sibling.text)
- num.append(each.td.next_sibling.next_sibling.text)
- i = i+1
- ws.append(["城市","单价(元/㎡)"])
- for i in range(0,len(name)-1):
- ws.append([name[i], num[i]])
- wb.save("data.xlsx")
温馨如xiaosi4081 ,我把数据分享出来:
 data.zip
(5.08 KB, 下载次数: 6, 售价: 5 鱼币)
data.zip
(5.08 KB, 下载次数: 6, 售价: 5 鱼币)
|
评分
-
查看全部评分
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-5-24 11:54:33
发表于 2020-5-24 11:54:33
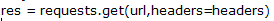

 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-5-24 12:05:59
发表于 2020-5-24 12:05:59
 楼主
楼主
