|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
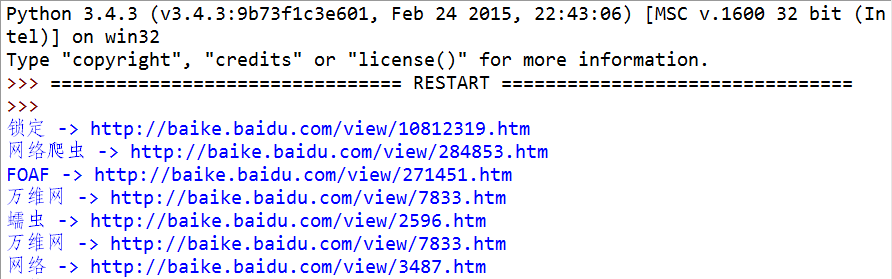
import urllib.request
import re
from bs4 import BeautifulSoup
def main():
url = "http://baike.baidu.com/view/284853.htm"
response = urllib.request.urlopen(url)
html = response.read()
soup = BeautifulSoup(html, "html.parser") # 使用 Python 默认的解析器
for each in soup.find_all(href=re.compile("view")):
print(each.text, "->", ''.join(["http://baike.baidu.com", each["href"]]))
# 上边用 join() 不用 + 直接拼接,是因为 join() 被证明执行效率要高很多
if __name__ == "__main__":
main()
这里面没讲bs4用法啊 直接就用了。。。而且代码出的结果不对,百度百科现在没有view了啊,应该怎么办呢 包括后面的作业,猪八戒那里也一样出错
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-5-25 11:44:38
发表于 2020-5-25 11:44:38

 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-5-25 11:47:50
发表于 2020-5-25 11:47:50

 楼主
楼主
