|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
##返回文件里所有某行某位置的匹配信息
def search_in_file(file_name, key): #search_in_file(路径, 关键字)
#f = open(file_name,encoding='unicode_escape')
f = open(file_name,encoding='utf-8')
count = 0 # 记录行数
key_dict = dict() # 字典,用户存放key所在具体行数对应具体位置
for each_line in f:
count += 1
if key in each_line:
pos = pos_in_line(each_line, key) # key在每行对应的位置
key_dict[count] = pos
f.close()
return key_dict
代码如上:
报错信息
Traceback (most recent call last):
File "D:/pycharmprojects/fisherctest.py", line 329, in <module>
search_files(key, detail)
File "D:/pycharmprojects/fisherctest.py", line 319, in search_files
key_dict = search_in_file(each_txt_file, key)
File "D:/pycharmprojects/fisherctest.py", line 298, in search_in_file
for each_line in f:
File "D:\Python3.7\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb4 in position 0: invalid start byte
尝试了百度上的几种方法,无果,有解决类似转码问题的大佬求支招
可以先检测文件的编码格式。
下面代码是检测编码格式的。
可能需要先安装chardet模块,看个人情况,或许你安装的python已经有chardet模块了
- import chardet
- f = open(file_name,'rb') # 先用二进制打开
- data = f.read() # 读取文件内容
- file_encoding = chardet.detect(data).get('encoding') # 得到文件的编码格式
- f.close()
- print(file_encoding)
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-7-2 21:58:12
发表于 2020-7-2 21:58:12
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-7-2 22:11:53
发表于 2020-7-2 22:11:53

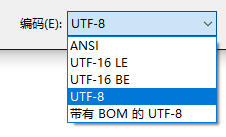
 发表于 2020-7-2 22:20:21
发表于 2020-7-2 22:20:21

 楼主
楼主 了解了解,就是这么处理的
了解了解,就是这么处理的