|
2333| 9
|
[已解决]为什么会这样呢?,怎么无法读取该TXT文本的数据呢 |
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
| ||
|
小甲鱼最新课程 -> https://ilovefishc.com
|
||
小黑屋|手机版|Archiver|鱼C工作室
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
GMT+8, 2026-7-15 12:40
Powered by Discuz! X3.4
© 2001-2023 Discuz! Team.


 狗仔卡
狗仔卡 发表于 2020-7-16 18:45:08
发表于 2020-7-16 18:45:08




 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-7-16 18:48:49
发表于 2020-7-16 18:48:49
 发表于 2020-7-16 18:50:07
发表于 2020-7-16 18:50:07
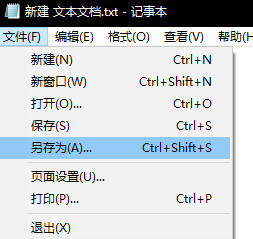

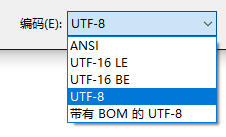
 楼主
楼主 看来先阶段只能先绕过这个了,学到后边在回过来来看看吧
看来先阶段只能先绕过这个了,学到后边在回过来来看看吧
