|
|

楼主 |
发表于 2020-8-13 23:13:31
|
显示全部楼层
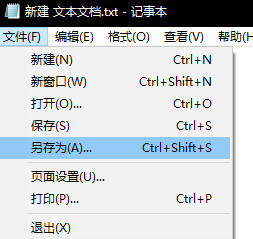
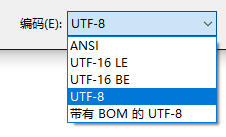
我上网查了下,好像原因是因为什么版本的改动开始区分bytes 和 str了,然后我按照百度上的指导把代码改成了:
>>> for each in f:
each = str(each,encoding = 'utf-8')
print(each)
list2 = each.split(':', 1)[1]
if each[:6] != '======':
if each[1] =='甲':
boy.append(list2)
else:
girl.append(list2)
else:
f1 = open('/Users/asdfasd/Downloads' + 'boy_' + str(countboy) +'.txt','wb')
f2 = open('/Users/asdfasd/Downloads' + 'boy_' + str(countboy) + '.txt','wb')
f1.close()
f2.close()
for each in boy:
f1.writeline(each)
for each in girl:
f2.writeline(each)
boy = []
girl = []
countboy += 1
countgirl += 1
结果仍然报错:
Traceback (most recent call last):
File "<pyshell#135>", line 1, in <module>
for each in f:
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbf in position 2: invalid start byte
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2020-8-13 22:57:35
发表于 2020-8-13 22:57:35
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-8-13 23:01:34
发表于 2020-8-13 23:01:34


 发表于 2020-8-14 11:23:29
发表于 2020-8-14 11:23:29