|
|
ВнЙПЧўІбЈ¬ҪбҪ»ёь¶аәГУСЈ¬ПнУГёь¶а№ҰДЬ^_^
ДъРиТӘ өЗВј ІЕҝЙТФПВФШ»тІйҝҙЈ¬Г»УРХЛәЕЈҝБўјҙЧўІб
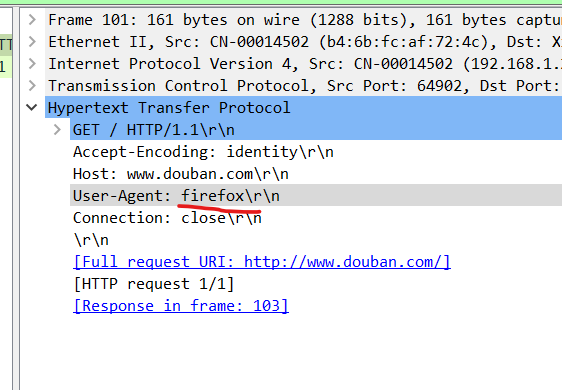
x
- response = urllib.request.urlopen("http://www.douban.com")
- Traceback (most recent call last):
- File "<pyshell#1>", line 1, in <module>
- response = urllib.request.urlopen("http://www.douban.com")
- File "D:\ОДјю\Python38\lib\urllib\request.py", line 222, in urlopen
- return opener.open(url, data, timeout)
- File "D:\ОДјю\Python38\lib\urllib\request.py", line 531, in open
- response = meth(req, response)
- File "D:\ОДјю\Python38\lib\urllib\request.py", line 640, in http_response
- response = self.parent.error(
- File "D:\ОДјю\Python38\lib\urllib\request.py", line 569, in error
- return self._call_chain(*args)
- File "D:\ОДјю\Python38\lib\urllib\request.py", line 502, in _call_chain
- result = func(*args)
- File "D:\ОДјю\Python38\lib\urllib\request.py", line 649, in http_error_default
- raise HTTPError(req.full_url, code, msg, hdrs, fp)
- urllib.error.HTTPError: HTTP Error 418:
ДгҝЙТФКФКФХвСщ - import requests
- url = 'https://book.douban.com/'
- response = requests.get(url)
- print(response.text)
|
|
 ( ФБICPұё18085999әЕ-1 | ФБ№«Нш°Іұё 44051102000585әЕ)
( ФБICPұё18085999әЕ-1 | ФБ№«Нш°Іұё 44051102000585әЕ)

 №·ЧРҝЁ
№·ЧРҝЁ ·ўұнУЪ 2020-9-5 08:47:47
·ўұнУЪ 2020-9-5 08:47:47
 ЦГ¶ҘҝЁ
ЦГ¶ҘҝЁ З§Ҫп¶Ҙ
З§Ҫп¶Ҙ ПФЙнҝЁ
ПФЙнҝЁ
 ·ўұнУЪ 2020-9-7 18:36:32
·ўұнУЪ 2020-9-7 18:36:32