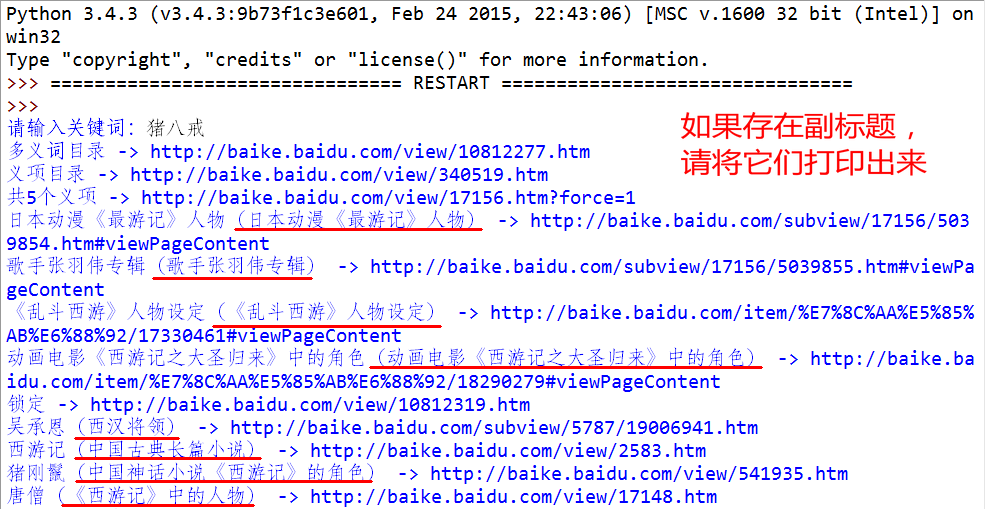
|
|
10鱼币
- import urllib.request
- import urllib.parse
- import re
- from bs4 import BeautifulSoup
- import random
- import time
- def main():
- ## keyword = input("请输入关键词:")
- keyword = urllib.parse.urlencode({"word":'猪八戒'})
-
- url = ("http://baike.baidu.com/search/word?%s" % keyword)
- iplist = ['113.28.90.67:9480']
- proxy_support = urllib.request.ProxyHandler({'http':random.choice(iplist)})
- opener = urllib.request.build_opener(proxy_support)
- opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')]
- urllib.request.install_opener(opener)
-
- response = urllib.request.urlopen(url)
- html = response.read().decode('UTF-8')
- soup = BeautifulSoup(html,"html.parser")
- for each in soup.find_all(href=re.compile("view")):
- content = ''.join([each.text])
- url2 = ''.join(["http://baike.baidu.com",each["href"]])
-
- response2 = urllib.request.urlopen(url2)
- html2 = response2.read().decode('UTF-8')
- soup2 = BeautifulSoup(html2,"html.parser") #从网页抓取数据
- if soup2:
- content = ''.join([content, soup2.h2.text])
- content = ''.join([content, " -> ", url2])
- print(content)
- time.sleep(3)
- if __name__ == "__main__":
- main()
运行结果总是:UnicodeEncodeError: 'ascii' codec can't encode characters in position 58-61: ordinal not in range(128)
求问题出在哪里了?
我在你的另一个帖子里回答过了,是转码问题,你自己去看一下吧
|
最佳答案
查看完整内容
我在你的另一个帖子里回答过了,是转码问题,你自己去看一下吧
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2021-12-29 09:08:17
发表于 2021-12-29 09:08:17
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2021-12-29 09:08:18
发表于 2021-12-29 09:08:18

 楼主
楼主