|
|
马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
本帖最后由 atrago 于 2022-3-2 17:37 编辑
操作环境:Jupyter Notebook
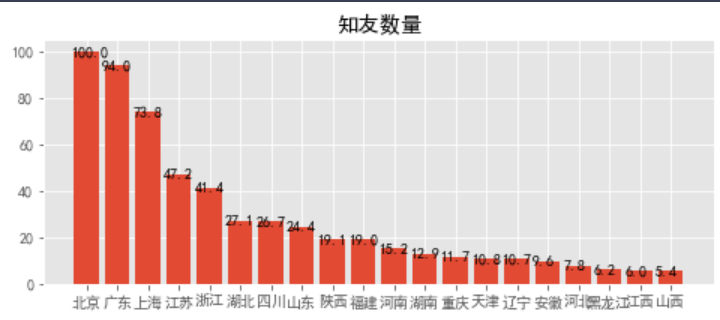
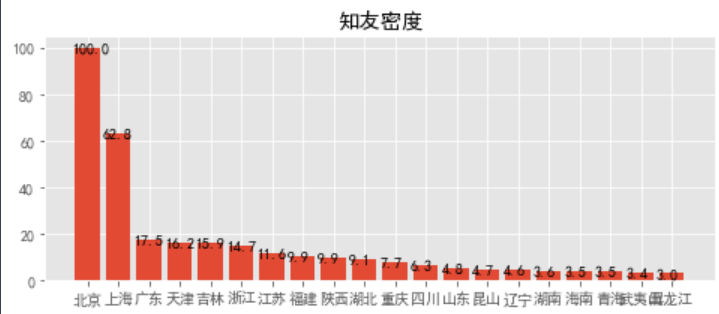
清洗知乎数据csv格式文件分析知乎Top20知友数量全国分布情况和知友密度情况
利用Numpy模块,Pandas模块进行数据清洗,Matplotlib模块将数据可视化
成功得到知友数量全国分布情况和知友密度情况图表数据
目的:
① 按照地域统计 知友数量、知友密度(知友数量/城市常住人口)
② 知友数量,知友密度,标准化处理
③ 图表可视化
标准化计算方法 = (X - Xmin) / (Xmax - Xmin)
困难及解决方案:
1、获取数据后对数据格式排列没有清洗的概念,不知道如何两个表格数据进行合并;查询利用Numpy模块中的merge函数。
2、可视化标签设置错误;查阅matplotlib.pyplot相关阅读指导进行改。
结果:
改进计划:
1、优化代码结构逻辑
2、将函数封装成模块
Code:
- import numpy as ny
- import pandas as pd
- import matplotlib.pyplot as plt
- import matplotlib as mpl
- %matplotlib inline
- #设置图形内嵌
- import matplotlib.style as stl
- stl.use('ggplot') #自带样式美化
- mpl.rcParams['font.sans-serif']=['SimHei'] # #指定默认字体 SimHei为黑体
- #mpl.rcParams['axes.unicode_minus']=False # #用来正常显示负号
- #读取数据
- data1 = pd.read_csv('知乎数据_201701.csv',engine='python')
- data2 = pd.read_csv('六普常住人口数.csv',engine='python')
- def fun1(df):#清洗缺失值
- cols = df.columns #获取列
- for each in cols:
- if df[each].dtype == 'object':
- df[each].fillna('Missing',inplace = True)
- else:
- df[each].fillna(0,inplace = True)
- return df
- data1_d = fun1(data1)#处理数据,清空Nan
- #data1_d.head(5)
- data_city = data1_d.groupby('居住地').count()#按居住地分组
- #print(data_city.head())
- data2['city'] = data2['地区'].str[:-1]
- #data2['city'].head()
- qldata = pd.merge(data_city,data2,left_index=True,right_on='city')[['_id','city','常住人口']]
- qldata['密度'] = qldata['_id'] / qldata['常住人口']
- #表合并
- def fun2(df,*cols):#求标准化函数封装
- colnames = []
-
- for each in cols:
- colname = each + 'norm'
- df[colname] = ((df[each] - df[each].min()) / (df[each].max() -df[each].min())) *100 #标准化公式
- colnames.append(colname)
-
- return df,colnames
- result = fun2(qldata,'_id','密度')[0] #处理后图表
- result_colname = fun2(qldata,'_id','密度')[1] #标签名
- #知友数量-城市分布数据
- result_num_Top20 = qldata.sort_values(result_colname[0],ascending=False)[[result_colname[0],'city']][:20]
- #知友密度-城市分布数据
- result_den_Top20 = qldata.sort_values(result_colname[1],ascending=False)[[result_colname[1],'city']][:20]
- #print(result_num_Top20[result_colname[0]])
- def fun3(dk,x,y,name,n):#生成图表函数封装
- fig= plt.figure(num = n,figsize=(8,3))
- plt.bar(range(20),y,tick_label = x)
- plt.title(name)
- for i,j in zip(range(20),y):#添加标签
- plt.text(i-0.5,j-2,'%.1f'% j,fontsize=10)
- fun3(result_num_Top20,result_num_Top20['city'],result_num_Top20[result_colname[0]],'知友数量',1)#表1
- fun3(result_den_Top20,result_den_Top20['city'],result_den_Top20[result_colname[1]],'知友密度',2)#表2
附件如下:
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2022-3-2 17:14:31
发表于 2022-3-2 17:14:31

 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡