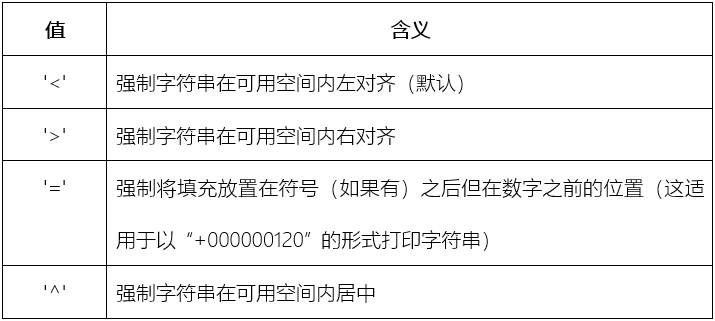
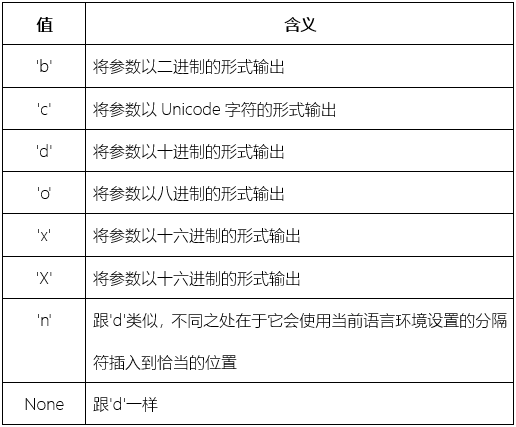
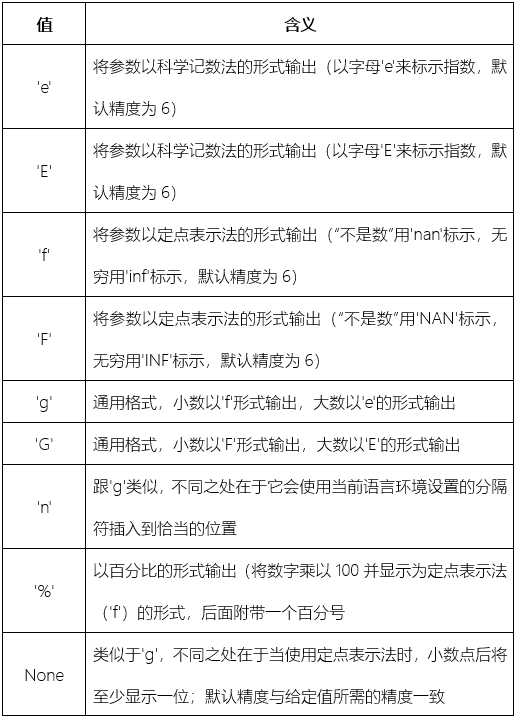
|
|

楼主 |
发表于 2022-12-15 23:13:25
|
显示全部楼层
本帖最后由 成成是我 于 2022-12-16 14:39 编辑
2022.12.15
all() 函数是判断可迭代对象中是否所有元素的值都为真,any() 函数则是判断可迭代对象中是否存在某个元素的值为真。
enumerate() 函数用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从 0 开始的序号共同构成一个二元组的列表,可加入start参数,enumerate() 函数生成的是一个 enumerate 枚举对象,而非迭代器,所以不能使用下标对其进行随机访问
- >>> seasons = ["Spring", "Summer", "Fall", "Winter"]
- >>> list(enumerate(seasons))
- [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
zip() 函数(拉链)用于创建一个聚合多个可迭代对象的迭代器,做法是将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第 i 个元组包含来自每个参数的第 i 个元素。
如果传入的可迭代对象长度不一致,那么将会以最短的那个为准,如果那些值对于我们来说是有意义的,我们可以使用 itertools 模块的 zip_longest() 函数来代替
- >>> import itertools
- >>> zipped = itertools.zip_longest(x, y, z)
- >>> list(zipped)
- [(1, 4, 'F'), (2, 5, 'i'), (3, 6, 's'), (<font color="#ff0000">None, None</font>, 'h'), (<font color="#ff0000">None, None</font>, 'C')]
map() 函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器,如果指定的函数需要两个参数,后面跟着的可迭代对象的数量也应该是两个,如果可迭代对象的长度不一致,那么 Python 采取的做法跟 zip() 函数一样,都是在最短的可迭代对象终止时结束
与 map() 函数类似,filter() 函数也是需要传入一个函数作为参数,不过 filter() 函数是根据提供的函数,对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回,如果提供的函数是 None,则会假设它是一个 “鉴真” 函数,即可迭代对象中所有值为假的元素会被移除
可迭代对象和迭代器:一个迭代器肯定是一个可迭代对象,最大的区别是:可迭代对象咱们可以对其进行重复的操作,而迭代器则是一次性的!,通过 type() 函数,可以观察到这个区别
将可迭代对象转换为迭代器:iter() 函数
next() 函数,它是专门针对迭代器的,它的作用就是逐个将迭代器中的元素提取出来(返回迭代器下一个项目,一次只能访问一个),添加第二个字符串参数,异常时弹出
异常可控,错误不可控
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2022-11-24 11:20:30
发表于 2022-11-24 11:20:30
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2022-12-1 10:35:43
发表于 2022-12-1 10:35:43