|
|
 发表于 2023-1-4 11:16:22
|
显示全部楼层
发表于 2023-1-4 11:16:22
|
显示全部楼层
本帖最后由 阿奇_o 于 2023-1-4 11:23 编辑
似乎没啥难度,直来直去,即可
- import requests, re
- response = requests.get('https://www.woyaotingshu.com/play/5440-0-1.html')
- # response.text # 看看,直接就有播放器的请求地址
- html = response.text
- ym = 'https://www.woyaotingshu.com'
- url_jplayer = re.findall('<iframe .*?src="(/jplayer.*?)" width', html)[0]
- res = requests.get(ym + url_jplayer)
- # res.text # 再看看,MP3音频资源url,也有
- mp3 = re.findall('{mp3:"(http://.*?)",', res.text)[0]
- res_mp3 = requests.get(mp3)
- res_mp3.headers # Content-Type 就是音频资源(MP3)
- {'Content-Type': 'audio/mpeg', 'Last-Modified': 'Tue, 04 Jan 2011 16:00:00 GMT', 'Accept-Ranges': 'bytes', 'ETag': '"080b87028accb1:0"', 'Server': 'Microsoft-IIS/8.5', 'X-Powered-By': 'ASP.NET', 'Date': 'Wed, 04 Jan 2023 03:01:22 GMT', 'Content-Length': '4405125'}
- # 保存MP3
- with open('001第1篇第1集第01章_罗峰.mp3', 'wb') as f:
- f.write(res_mp3.content)
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡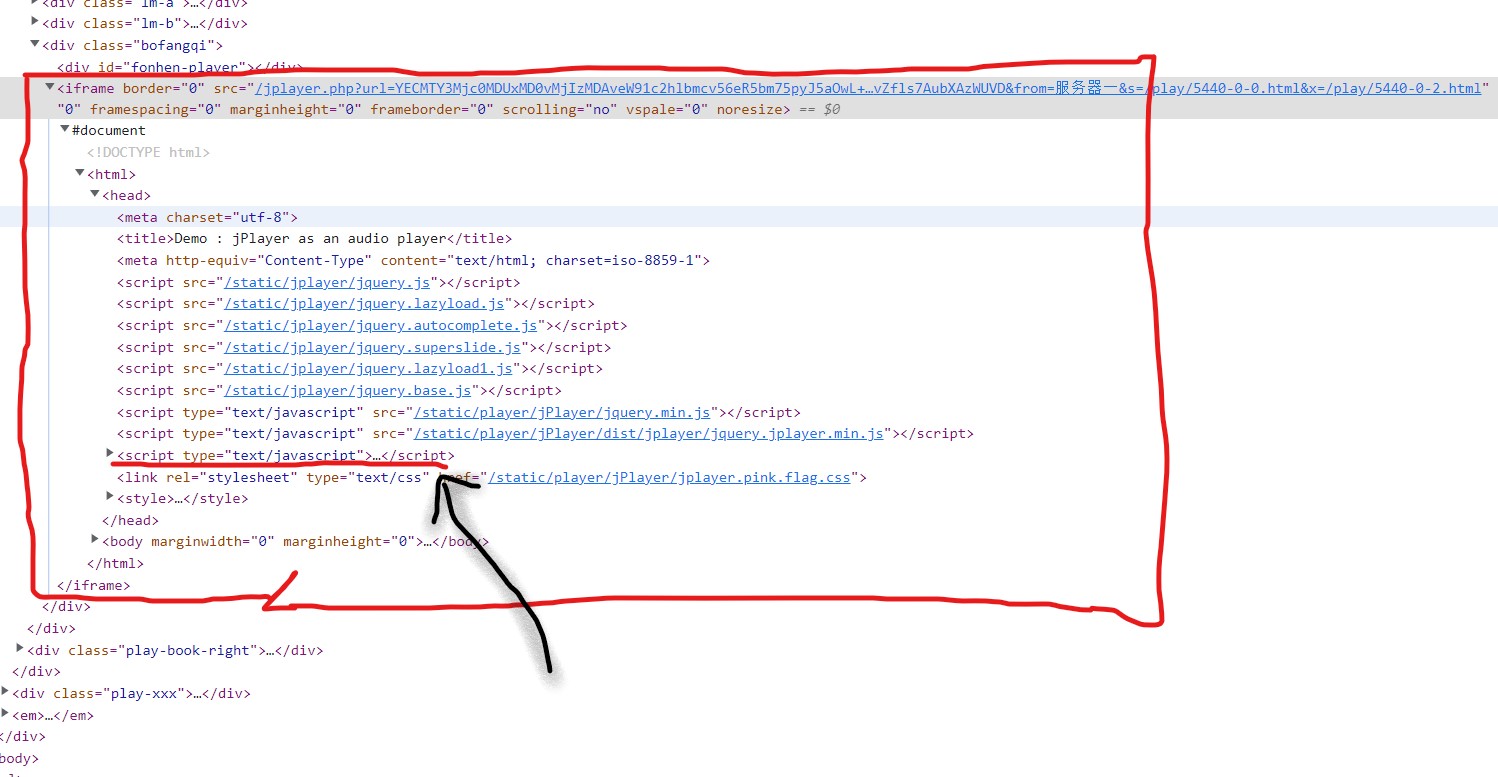
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2023-1-3 19:05:41
发表于 2023-1-3 19:05:41

 楼主
楼主