马上注册,结交更多好友,享用更多功能^_^
您需要 登录 才可以下载或查看,没有账号?立即注册
x
刚看到位兄弟也贴了份KMP算法说明,但本人觉得说的不是很详细,当初我在看这个算法的时候也看的头晕昏昏的,我贴的这份也是网上找的。
且听详细分解:
KMP字符串模式匹配详解 来自CSDN A_B_C_ABC 网友 KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。简单匹配算法的时间复杂度为O(m*n);KMP匹配算法。可以证明它的时间复杂度为O(m+n).。 一. 简单匹配算法 先来看一个简单匹配算法的函数: int Index_BF ( char S [ ], char T [ ], int pos ) { /* 若串 S 中从第pos(S 的下标0≤pos<StrLength(S))个字符 起存在和串 T 相同的子串,则称匹配成功,返回第一个 这样的子串在串 S 中的下标,否则返回 -1 */ int i = pos, j = 0; while ( S[i+j] != '\0'&& T[j] != '\0') if ( S[i+j] == T[j] ) j ++; // 继续比较后一字符 else { i ++; j = 0; // 重新开始新的一轮匹配 } if ( T[j] == '\0') return i; // 匹配成功 返回下标 else return -1; // 串S中(第pos个字符起)不存在和串T相同的子串 } // Index_BF
此算法的思想是直截了当的:将主串S中某个位置i起始的子串和模式串T相比较。即从 j=0 起比较 S[i+j] 与 T[j],若相等,则在主串 S 中存在以 i 为起始位置匹配成功的可能性,继续往后比较( j逐步增1 ),直至与T串中最后一个字符相等为止,否则改从S串的下一个字符起重新开始进行下一轮的"匹配",即将串T向后滑动一位,即 i 增1,而 j 退回至0,重新开始新一轮的匹配。
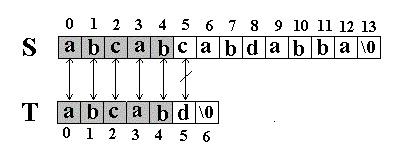
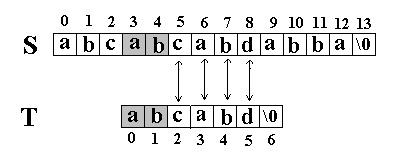
例如:在串S=”abcabcabdabba”中查找T=” abcabd”(我们可以假设从下标0开始):先是比较S[0]和T[0]是否相等,然后比较S[1] 和T[1]是否相等…我们发现一直比较到S[5] 和T[5]才不等。如图:
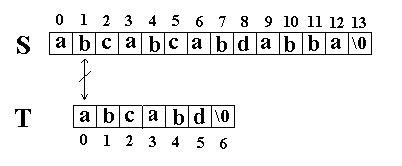
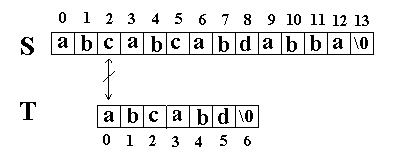
当这样一个失配发生时,T下标必须回溯到开始,S下标回溯的长度与T相同,然后S下标增1,然后再次比较。如图: 这次立刻发生了失配,T下标又回溯到开始,S下标增1,然后再次比较。如图:
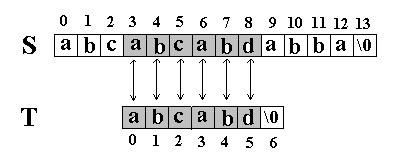
这次立刻发生了失配,T下标又回溯到开始,S下标增1,然后再次比较。如图: 又一次发生了失配,所以 T下标又回溯到开始, S下标增 1,然后再次比较。这次 T中的所有字符都和 S中相应的字符匹配了。函数返回 T在 S中的起始下标 3。如图:
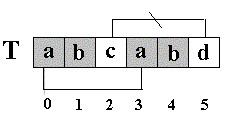
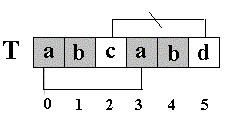
二. KMP匹配算法 还是相同的例子,在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5] 和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值(next[5]=2,为什么?后面讲),直接比较S[5] 和T[2]是否相等,因为相等,S和T的下标同时增加;因为又相等,S和T的下标又同时增加。。。最终在S中找到了T。如图: KMP匹配算法和简单匹配算法效率比较,一个极端的例子是: 在S=“AAAAAA…AAB“(100个A)中查找T=”AAAAAAAAAB”, 简单匹配算法每次都是比较到T的结尾,发现字符不同,然后T的下标回溯到开始,S的下标也要回溯相同长度后增1,继续比较。如果使用KMP匹配算法,就不必回溯. 对于一般文稿中串的匹配,简单匹配算法的时间复杂度可降为O (m+n),因此在多数的实际应用场合下被应用。 KMP算法的核心思想是利用已经得到的部分匹配信息来进行后面的匹配过程。看前面的例子。为什么T[5]==’d’的模式函数值等于2(next[5]=2),其实这个2表示T[5]==’d’的前面有2个字符和开始的两个字符相同,且T[5]==’d’不等于开始的两个字符之后的第三个字符(T[2]=’c’).如图: 也就是说,如果开始的两个字符之后的第三个字符也为’d’,那么,尽管T[5]==’d’的前面有2个字符和开始的两个字符相同,T[5]==’d’的模式函数值也不为2,而是为0。 前面我说:在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5] 和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值,直接比较S[5] 和T[2]是否相等。。。为什么可以这样? 刚才我又说:“(next[5]=2),其实这个2表示T[5]==’d’的前面有2个字符和开始的两个字符相同”。请看图 :因为,S[4] ==T[4],S[3] ==T[3],根据next[5]=2,有T[3]==T[0],T[4] ==T[1],所以S[3]==T[0],S[4] ==T[1](两对相当于间接比较过了),因此,接下来比较S[5] 和T[2]是否相等。。。 有人可能会问:S[3]和T[0],S[4] 和T[1]是根据next[5]=2间接比较相等,那S[1]和T[0],S[2] 和T[0]之间又是怎么跳过,可以不比较呢?因为S[0]=T[0],S[1]=T[1],S[2]=T[2],而T[0] != T[1], T[1] != T[2],==> S[0] != S[1],S[1] != S[2],所以S[1] != T[0],S[2] != T[0]. 还是从理论上间接比较了。 有人疑问又来了,你分析的是不是特殊轻况啊。 假设S不变,在S中搜索T=“abaabd”呢?答:这种情况,当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=-1,意思是S[2]已经和T[0] 间接比较过了,不相等,接下来去比较S[3]和T[0]吧。 假设S不变,在S中搜索T=“abbabd”呢?答:这种情况当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=0,意思是S[2]已经和T[2]比较过了,不相等,接下来去比较S[2]和T[0]吧。 假设S=”abaabcabdabba”在S中搜索T=“abaabd”呢?答:这种情况当比较到S[5]和T[5]时,发现不等,就去看next[5]的值,next[5]=2,意思是前面的比较过了,其中,S[5]的前面有两个字符和T的开始两个相等,接下来去比较S[5]和T[2]吧。 总之,有了串的next值,一切搞定。那么,怎么求串的模式函数值next[n]呢?(本文中next值、模式函数值、模式值是一个意思。)
|  ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡 发表于 2013-9-7 17:21:26
发表于 2013-9-7 17:21:26
 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 楼主
楼主