|
|
 发表于 2020-7-27 22:33:01
|
显示全部楼层
发表于 2020-7-27 22:33:01
|
显示全部楼层
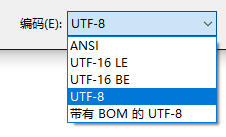
编码问题,这样应该可以了:
- import os
- initial=input('请输入待查找的目录:')
- key=input('请输入关键字:')
- for(root,dirs,file)in os.walk(initial):
- for each in file:
- count_line=0
- y=1
- z=0
- if os.path.splitext(each)[1]=='.txt':
- try:
- file1=open(os.path.join(root,each))
- except Exception:
- file1 = open(os.path.join(root, each), encoding='utf-8')
- for each_line in file1:
- count_line+=1
- count_index=[]
- x=0
- for i in range(len(each_line)):
- if each_line[i:i+len(key)]==key:
- count_index.append(i)
- x=z=1
- if x:
- if y:
- print('在文件【{0}】中找到关键字【{1}】'.format(os.path.join(root,each),key))
- y=0
- print('关键字出现在第{0}行,第{1}个位置。'.format(count_line,count_index))
- if z:
- print('=================================================')
|
|
 ( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)
( 粤ICP备18085999号-1 | 粤公网安备 44051102000585号)

 狗仔卡
狗仔卡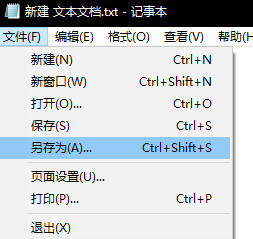

 置顶卡
置顶卡 千斤顶
千斤顶 显身卡
显身卡 发表于 2020-7-27 22:24:50
发表于 2020-7-27 22:24:50
 楼主
楼主
